Legibility and Feedback
When a controller is to be operated while not being seen, legibility of sensors/inputs and feedback of action are important considerations.
Legibility refers to how do you know what control does what? This may indicated through its shape, texture, and relational configuration or orientation. Regarding configuration: How are the controls oriented with respect to each other/themselves? How are the controls oriented with respect to the body? How is the entire controller oriented with respect to the body?
Feedback refers to how do you know you’ve done something? Without sight, this could be communicated through sound or touch and haptics. Haptics may be additional feedback beyond any physical alteration of the sensor itself, such as a vibration. But it may also be a result of the sensor itself. For example, a maintained push button will have a different feel relative to the enclosure when depressed versus released.
The Scale of Physical Interaction with an Object
As the controller is not seen while being operated, does that scale of interaction and controller increase? When controllers are considered as objects, interaction can occur the scale of the whole hand rather than individual fingers. Some initial thoughts I considered:
- Is it a glove interface between two hands? Touching different fingers together triggers different functions.
- Are objects held and placed down on a surface to trigger different events?
- Does an object have different faces which are touched to control different functions?
Sustained versus Momentary Interactions
How are interactions different when they are sporadic events such as momentarily pushing a button or flipping a switch versus a sustained interaction such as steadily holding down a button or shaking an object? What is the difference between an event-based interaction, and interaction of duration? Do each of these have different responses to the “directionality” of a controller or interaction?
Controllers
When considering the music controller at the scale of an object interacted with by the whole hand, I considered three scenarios.
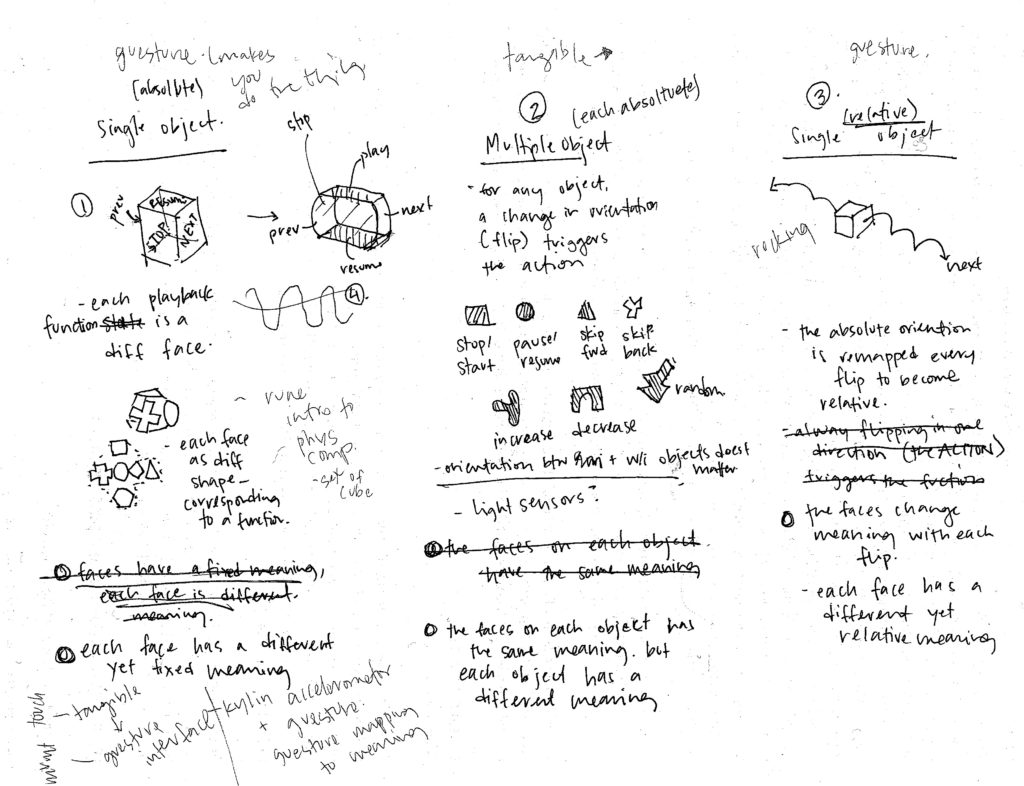
All Functions Concentrated into a Single Object, Functions are Fixed to Faces (Absolute Faces)
Different sides of an object trigger different commands. When all functions are combined into a single object, their configuration with respect to each other is important as the user must understand the orientation of the object itself. The tactile difference between each side is important for this orientation.
Further Development: Rather than a cube, does the object have two rounded sides for “previous” and “next” as they are momentary actions rather than sustained stairs? How is each face differentiated: many materials, texturing of the same material, shapes, etc.

Each Function is a Different Object (Absolute Objects)
Moving any object in any axis triggers the associated function. In this instance, orientation and configuration between objects does not matter, which allows individual users to configure the objects as desired. However, the legibility of each individual object is incredibly important as their shape, size and texture allows the user to discern one from the other.
Further Development: Explore different sets of objects: all the same material yet different forms versus all different textures but the same form
All Functions Concentrated into a Single Object, Functions are Associated with Gesture and Direction (Relative Faces)
Similar to the first consideration, all functions exist within one object. However, the functions are not fixed to faces but rather the spatial direction or gesture. The orientation of the object is remapped after each gesture in order to allow it to occur in succession.
Currently in development
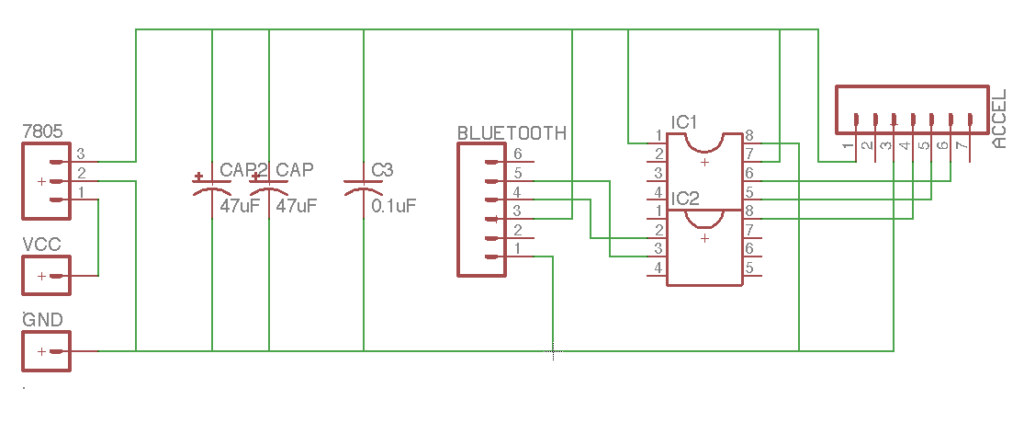
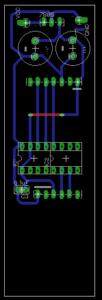
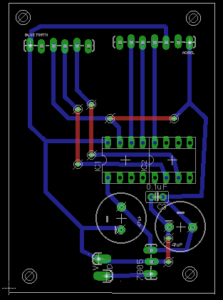
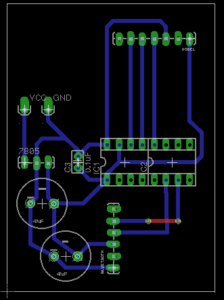
Circuit Boards
Keen to develop the enclosures further after this week, I chose to mill the circuit boards and use AtTiny84s as the microcontrollers. As the controller is based around interacting with an object, I prioritized making them wireless and configuring different setups in order to fabrication with a number of different enclosures.