Drawing Between Joints
A new skeleton is created by forming connections between joints that are otherwise unconnected in our physical reality. These new connections are toggled on an off by touching the select joints together. As the simulated skeleton on screen does not reflect our physical/bodily constrains, it’s interesting to watch the movement of an individual without seeing the digital corresponding counterpart.
Some further design decisions to explore:
Does the speed in touching the joints together affect the type/quality of line? Are they thick when slow and thin when fast?
Do the lines fade overtime, which in turn causes repeated touching of the same joints? (A dance emerges through repetition?)
How people think about time and space, and about things and processes, will be greatly influenced by the grammatical features of their language.
– Postman, 1985: 10
While provocative, Postman in effect summarizes McLuhan’s original proposition that “the medium is the message” but loads it with a value proposition, failing to present any evidence to support this subjective self-described “lamentation”. (Postman, 1985: 8). Rather than present an analysis of society’s current media landscape, Postman presents an “end-of-society” point of view in which he sees the rise of one media over another. This position presents an “either/or” scenario in which both typography (print, speech) cannot exist concurrently with television (image, sound, video). In discussing how his argument originates from studying the Bible, he writes, “The God of the Hews was to exist in the Word and through the Word, an unprecedented conception requiring the highest order of abstract thinking. Iconography thus became blasphemy so that a new kind of God could enter a culture.” (Postman, 1985: 9). However, this restriction to word over image is a method of controlling the distribution of the message. In this way, religion could be diseminent only to and through the literate and educated. However, image does not require this same level of literacy and its production was more widespread. As Postman places value of word over image, he attempts to continue this control over communication to a selected group and protect this position over power, effectively gatekeeping “the message”.
Postman’s distain for image-based communication is driven by his notion that this medium itself cannot reflect an “elevated” level of discourse. He writes, “You cannot do political philosphy on television. Its form works against the content.” (Postman, 1985: 7), Yet his examples of this are troublesome and dismissive: Las Vegas as a model for future cities in which public discourse is through the form of entertainment; the presentation of news is only by ‘the beautiful’ who disregard their scripts and research; and “fat people are effectively excluded from running for high political office.” (Postman, 1985: 4) He even admits that these examples are clichés! This lack of substaintial evidence for his argument is explict in his blasé approach to citing references. Without bothering to find the original source, he writes, “We are all, as Huxley says someplace, Great Abbreviators” (Postman, 1985: 6). Unfortunately, this approach is common throughout the entire chapter and leads to an antedotal argument.
This is not to say that Postman does not present valuable thoughts. The idea that what tools a culture uses to communicate fundamentally influence “the formation of the culture’s intellectual and social preoccupations” is insightful (Postman, 1985: 9). Yet, McLuhan, and later Langdon Winner in “Do Artifacts Have Politics?” (1980) both discuss this point without placing value judgements or declaring “end of the world” scenarios. Key to meaningful discussions of the media landscape and its effects is the decoupling of analysis from value judgement, something Postman fails to do in “The Medium is the Metaphor.”
Building on last week’s exercise, I expanded on the idea of a context-additive interface for navigating content. Rather than load a series of iframes with content from Wikipedia, as I did previously, I’ve created two arrays of data: one for ‘viewed content’ (the links clicked) and one for ‘potential data’ (the links that can be clicked). Ideally, this is content the user has added themselves (i.e. a database of blog posts) but for now I’ve pulled text from Wikipedia.
When a user clicks a link within an article, the corresponding content from the Potential Data array is added to the Viewed Data array, which populates the HTML page seen by the user. Rather than navigating away from the current block of content, the additional content is added horizontally in a set of increasingly-narrow columns.
When a controller is to be operated while not being seen, legibility of sensors/inputs and feedback of action are important considerations.
Legibility refers to how do you know what control does what? This may indicated through its shape, texture, and relational configuration or orientation. Regarding configuration: How are the controls oriented with respect to each other/themselves? How are the controls oriented with respect to the body? How is the entire controller oriented with respect to the body?
Feedback refers to how do you know you’ve done something? Without sight, this could be communicated through sound or touch and haptics. Haptics may be additional feedback beyond any physical alteration of the sensor itself, such as a vibration. But it may also be a result of the sensor itself. For example, a maintained push button will have a different feel relative to the enclosure when depressed versus released.
The Scale of Physical Interaction with an Object
As the controller is not seen while being operated, does that scale of interaction and controller increase? When controllers are considered as objects, interaction can occur the scale of the whole hand rather than individual fingers. Some initial thoughts I considered:
Is it a glove interface between two hands? Touching different fingers together triggers different functions.
Are objects held and placed down on a surface to trigger different events?
Does an object have different faces which are touched to control different functions?
Sustained versus Momentary Interactions
How are interactions different when they are sporadic events such as momentarily pushing a button or flipping a switch versus a sustained interaction such as steadily holding down a button or shaking an object? What is the difference between an event-based interaction, and interaction of duration? Do each of these have different responses to the “directionality” of a controller or interaction?
Controllers
When considering the music controller at the scale of an object interacted with by the whole hand, I considered three scenarios.
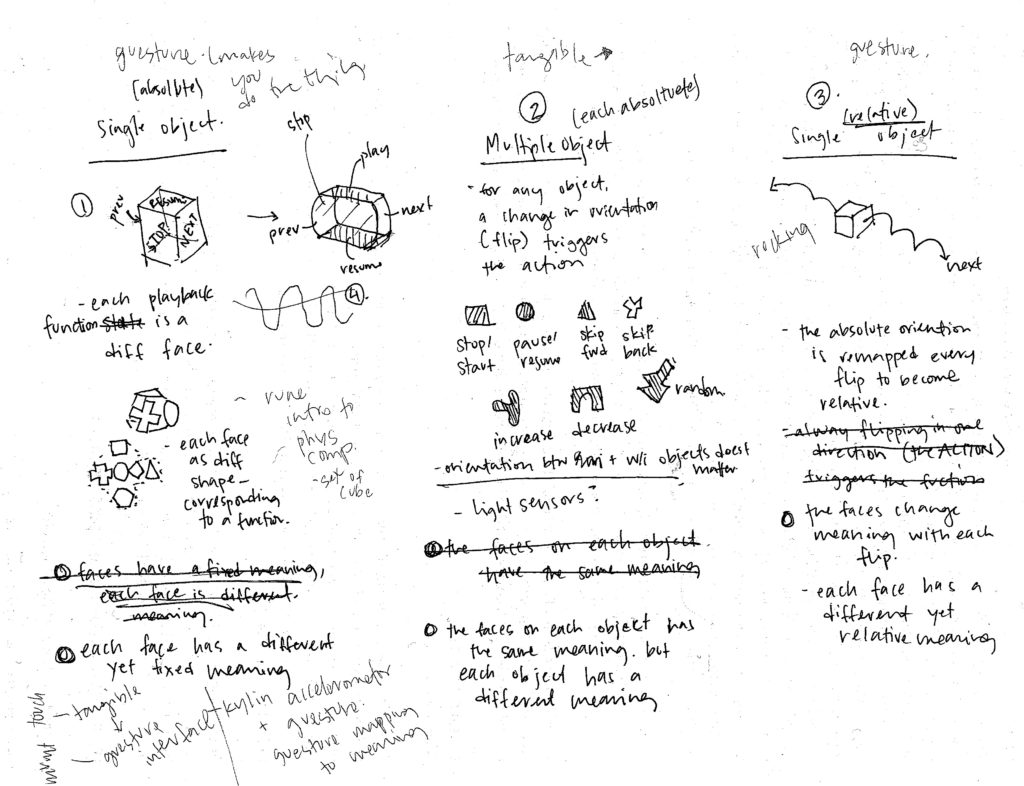
All Functions Concentrated into a Single Object, Functions are Fixed to Faces (Absolute Faces)
Different sides of an object trigger different commands. When all functions are combined into a single object, their configuration with respect to each other is important as the user must understand the orientation of the object itself. The tactile difference between each side is important for this orientation. Further Development: Rather than a cube, does the object have two rounded sides for “previous” and “next” as they are momentary actions rather than sustained stairs? How is each face differentiated: many materials, texturing of the same material, shapes, etc.
Single Object
Each Function is a Different Object (Absolute Objects)
Moving any object in any axis triggers the associated function. In this instance, orientation and configuration between objects does not matter, which allows individual users to configure the objects as desired. However, the legibility of each individual object is incredibly important as their shape, size and texture allows the user to discern one from the other. Further Development: Explore different sets of objects: all the same material yet different forms versus all different textures but the same form
All Functions Concentrated into a Single Object, Functions are Associated with Gesture and Direction (Relative Faces)
Similar to the first consideration, all functions exist within one object. However, the functions are not fixed to faces but rather the spatial direction or gesture. The orientation of the object is remapped after each gesture in order to allow it to occur in succession. Currently in development
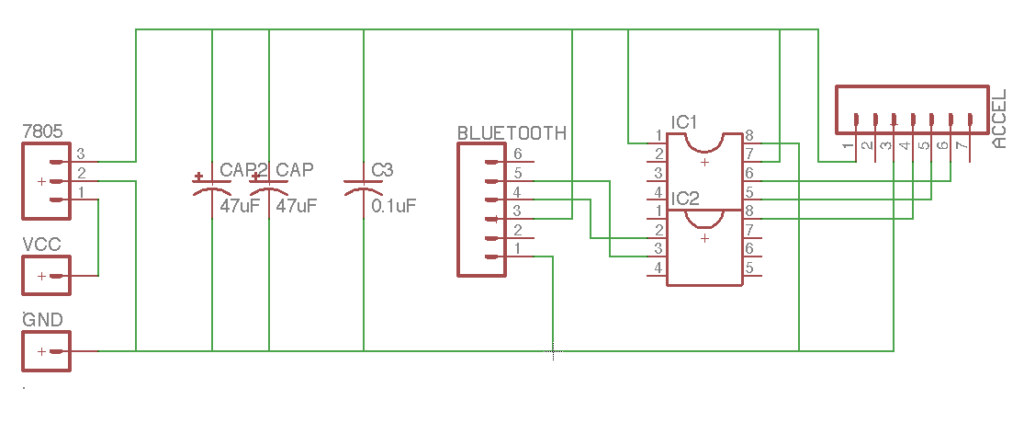
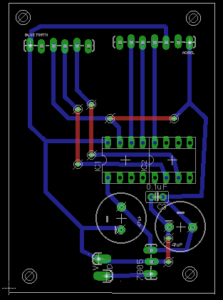
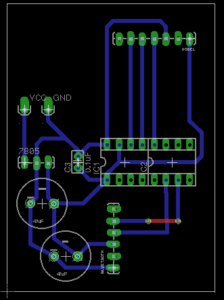
Schematic including socket for AtTiny84 and connection for 9V battery supply. Pins 5 and 4 on the Bluetooth connector are Rx and Tx respectively.
Circuit Boards
Keen to develop the enclosures further after this week, I chose to mill the circuit boards and use AtTiny84s as the microcontrollers. As the controller is based around interacting with an object, I prioritized making them wireless and configuring different setups in order to fabrication with a number of different enclosures.