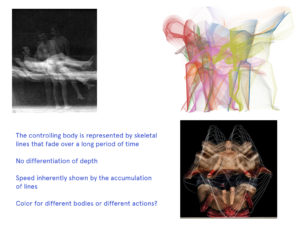
Since processing the text documents, I’ve been refining the goal of “finding latent (content and contextual) relationships within a large corpus of texts”. As the text remains a work in progress, I want to focus on how it has evolved and continues to evolve. A genealogical approach to text-relationships can be used to identify what pieces have been disregarded or ignored (and thus require further inspection) or identify the dominant tendancies and trains of thought.
Beyond looking at the past, I think this project can provide a foundation for developing a writing tool that moves beyond version control or collaborative commenting. Version control tends to provide a fine-grain binary approach: it compares two things and extracts the insertions or deletions. While this is helpful in an isolated scenario, I’m interested in broader developments across multiple objects over many time periods. Alternatively, version control also provides a high-level view indicating change-points over a long time, but those points of change are overly simplified – often represented by just a single dot. Without context or without knowing what specific time a change was made, this larger overview provides little information beyond the quantity and frequence of changes. Through a geneological and contextual approach to analyzing an existing body of text, I’m hoping to identify what sort of relationships could inform the writing and editing process.
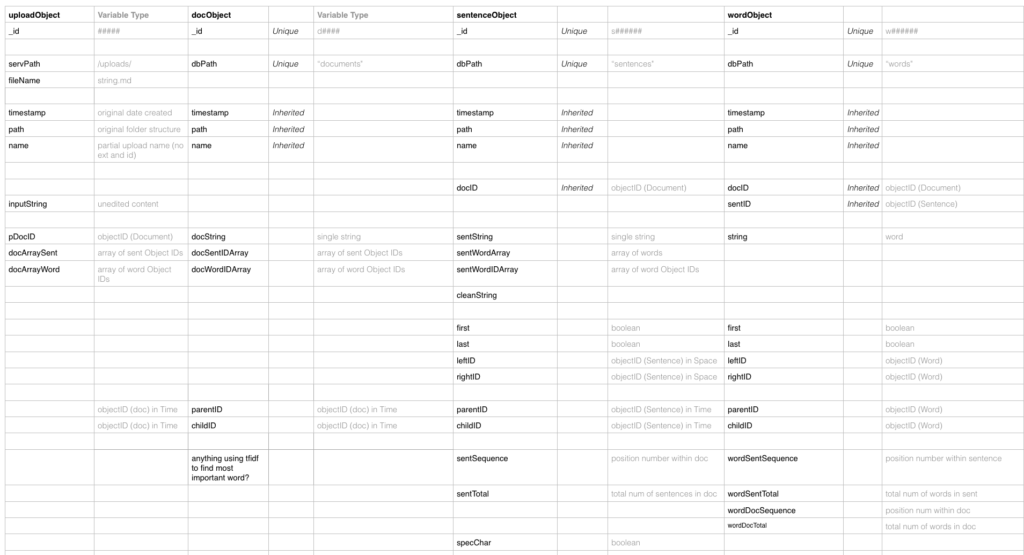
With all the data now added to the database, I’ve been exploring sentence similarity. The diagram below shows the process I’ve gone through up to this point.
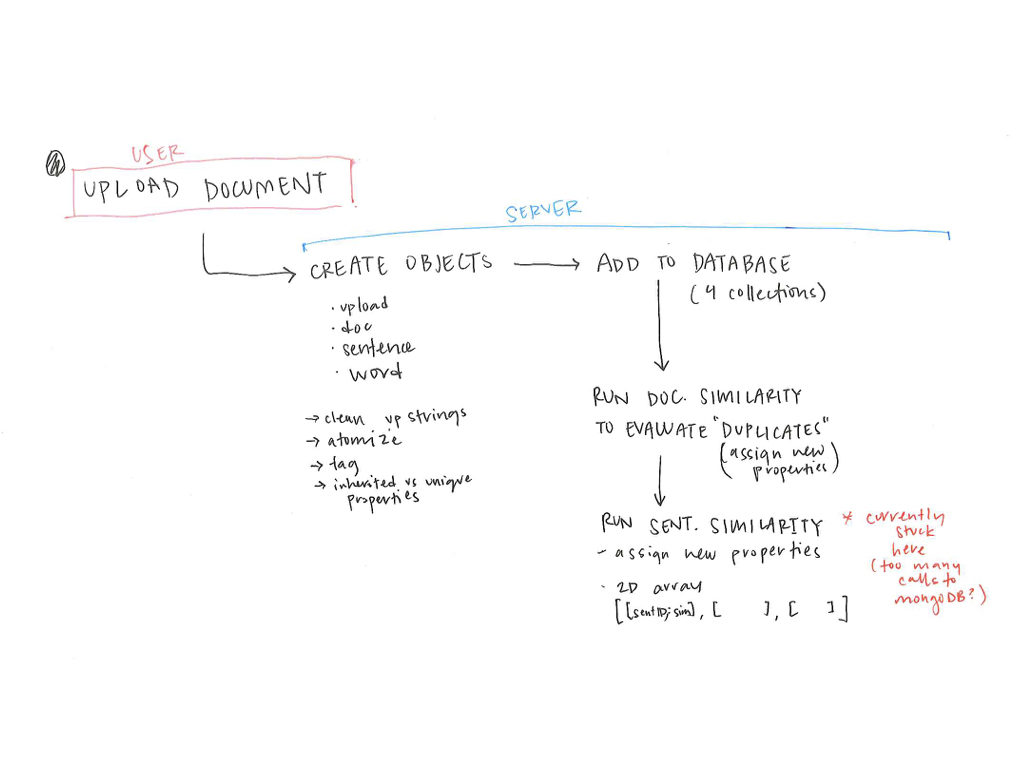
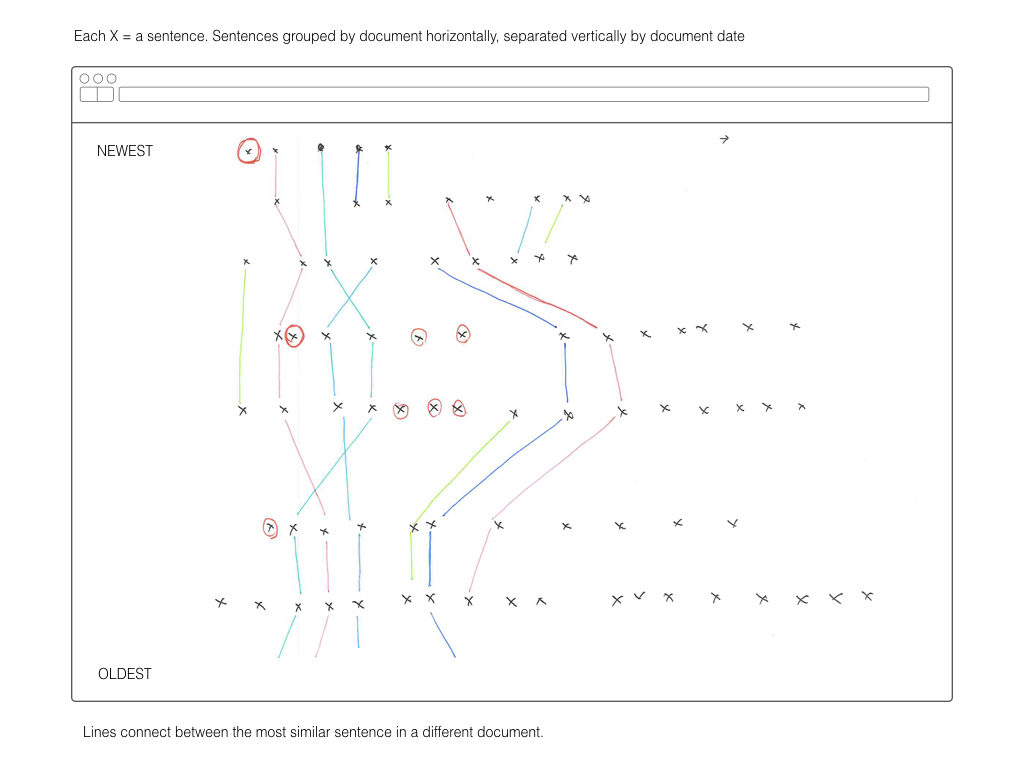
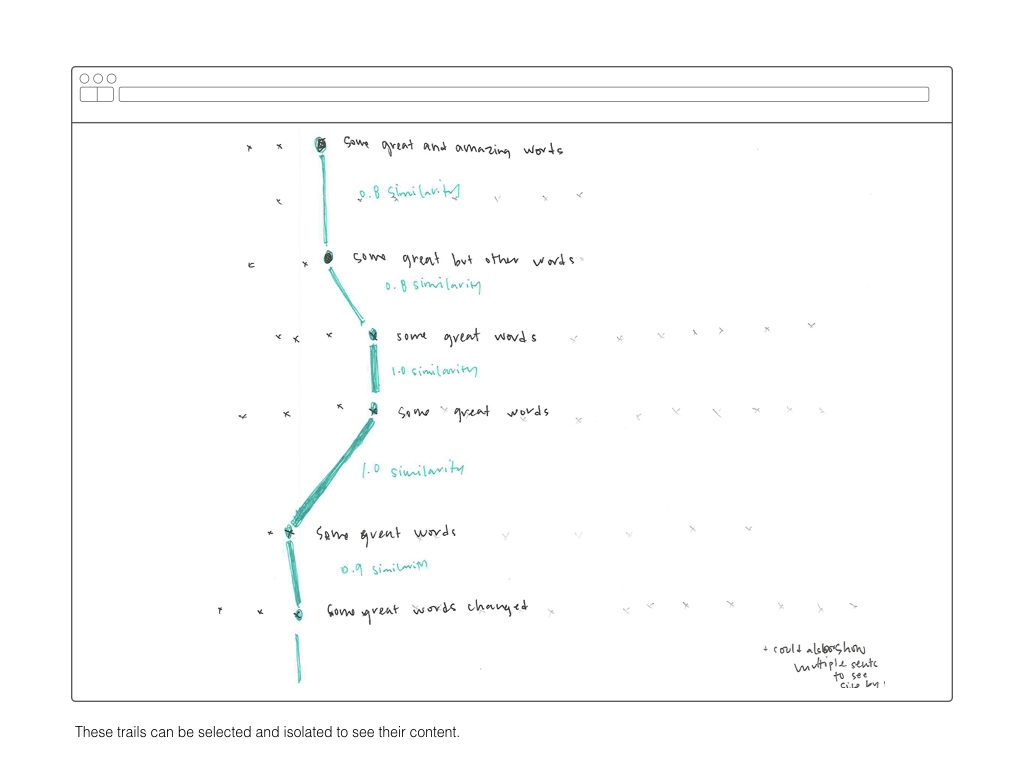
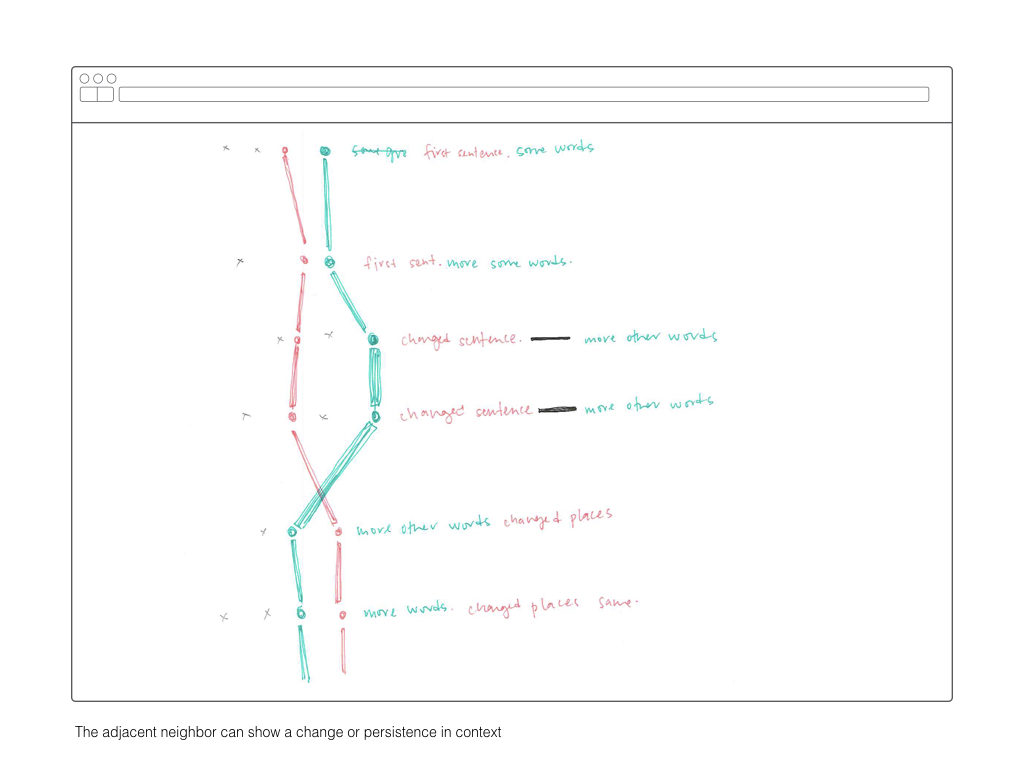
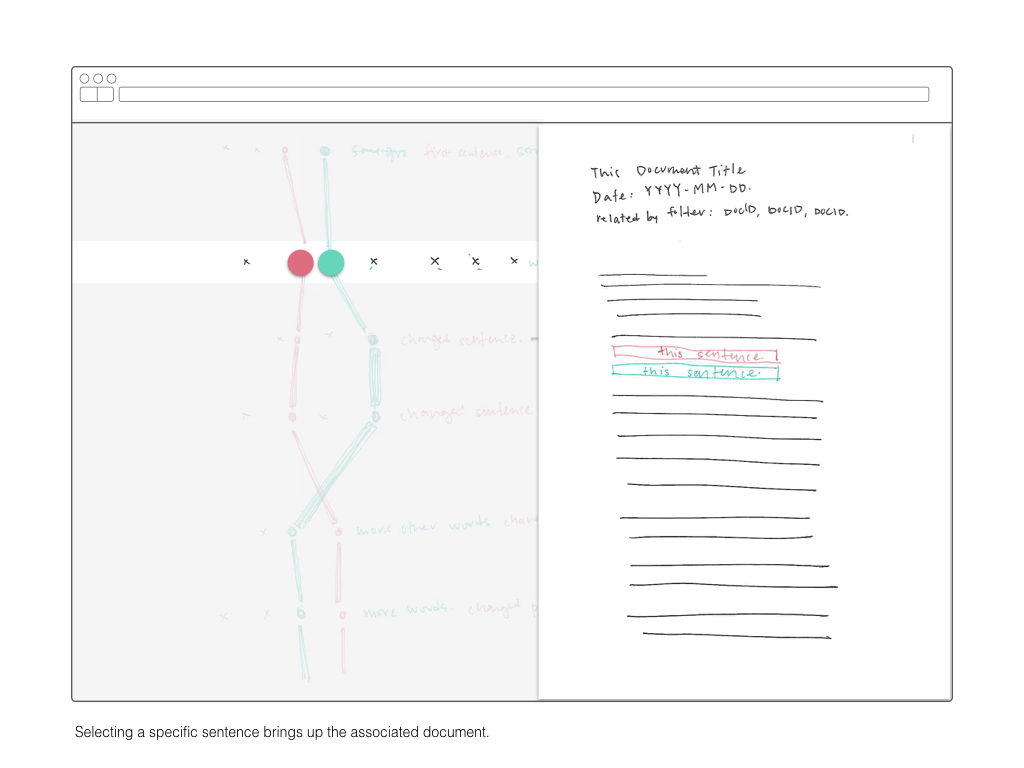
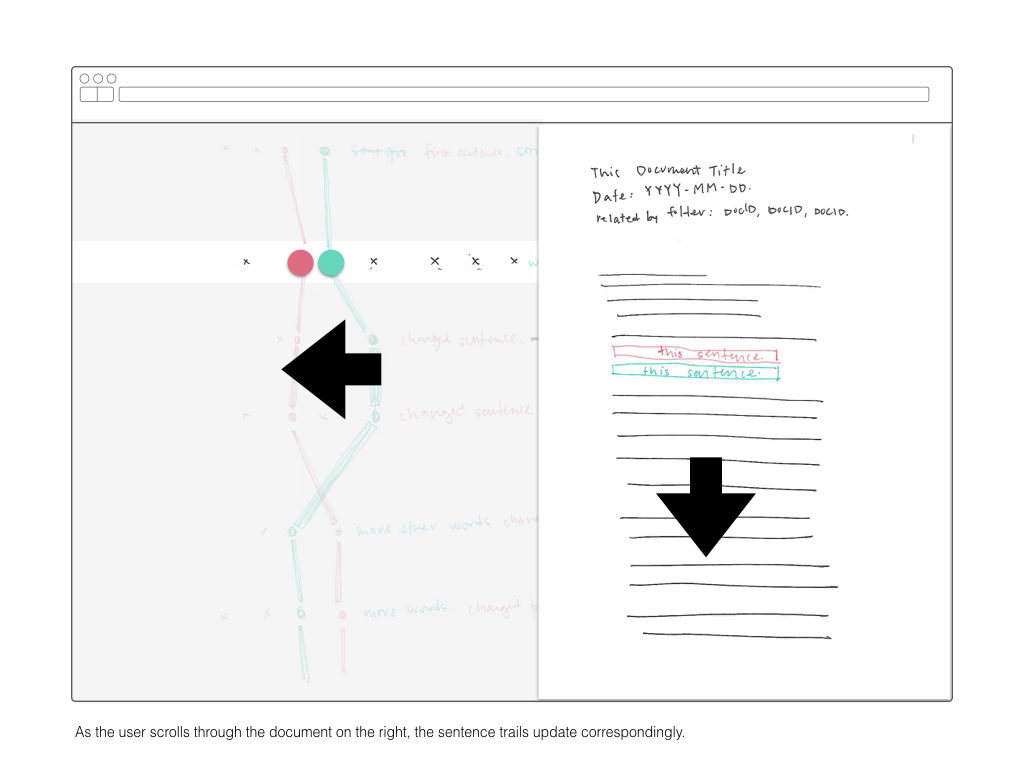
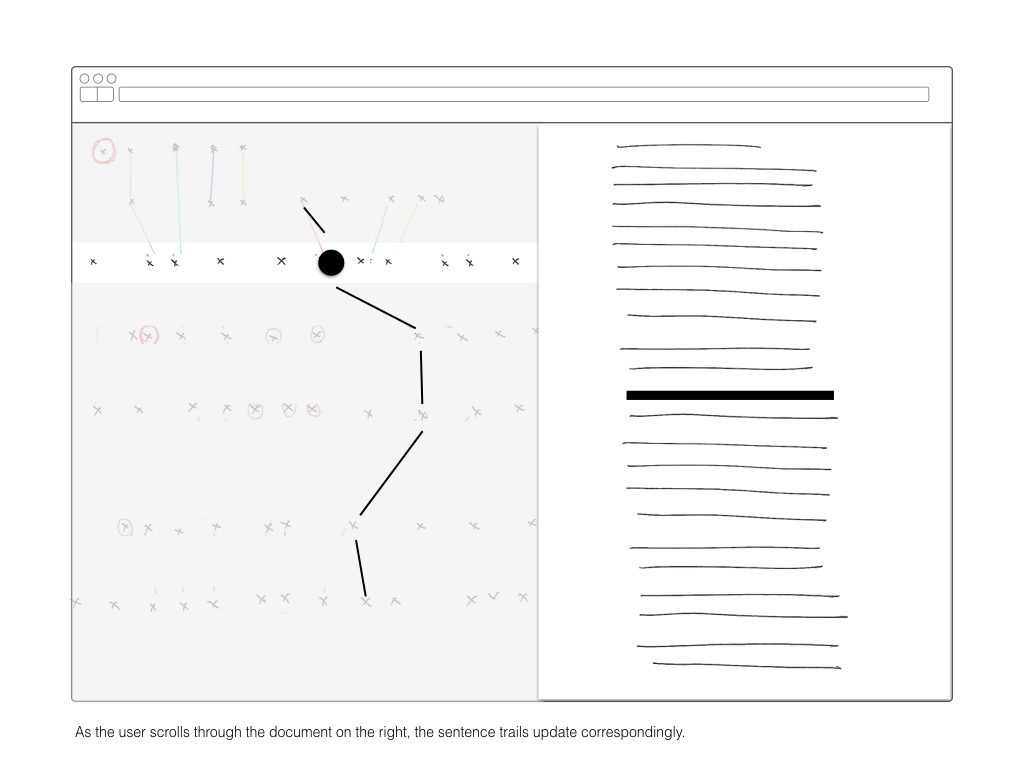
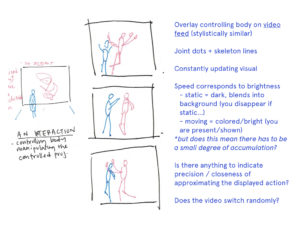
Once I’ve computed a two-dimensional array mapping the similarity of all sentences to each other, I plan on using that information to create visual interface for explore those relationships. The wireframes below are a rough sketch of what form this might take.