Are Pop Lyrics Getting More Repetitive
Documenting thoughts and works in progress

As I’ve discussed in previous posts, this project attempts to find relationships of dominant tenancies and abandon nodes within a large body of text. The large collection of text evolved in structure over time, thus examining at from a purely document-based approach is not appropriate.
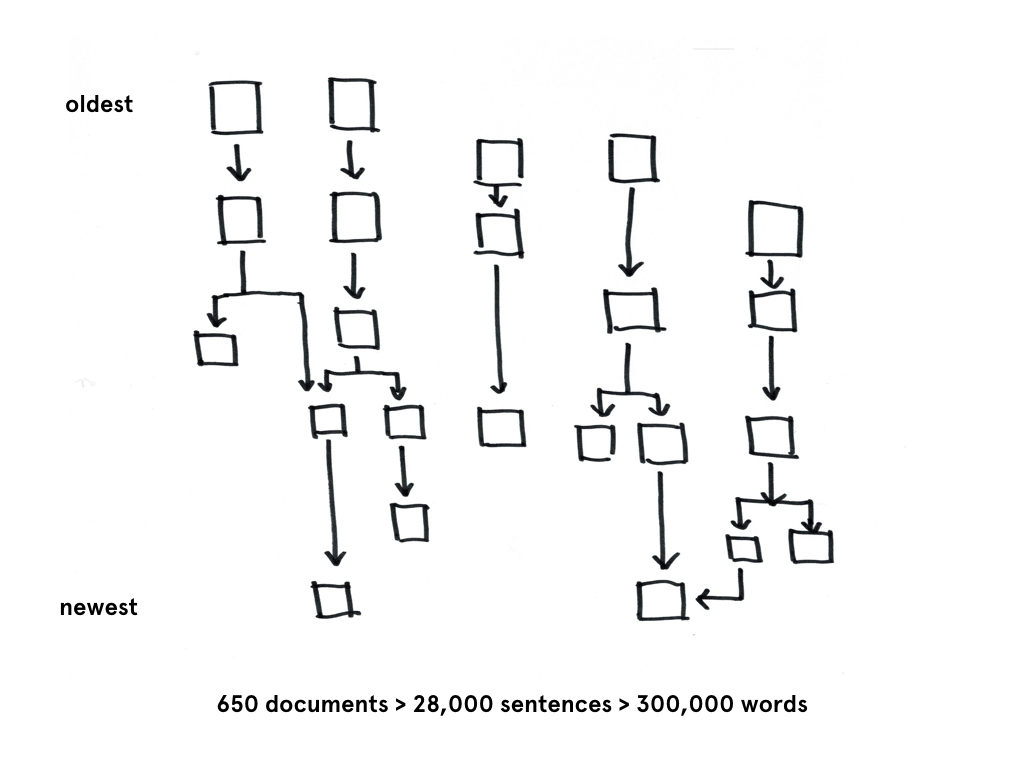 If the existing boundaries of a body of text are conventionally documents, this projects instead treats sentences as the primary object and attempts to draws new boundaries around sentences in various documents.
If the existing boundaries of a body of text are conventionally documents, this projects instead treats sentences as the primary object and attempts to draws new boundaries around sentences in various documents.
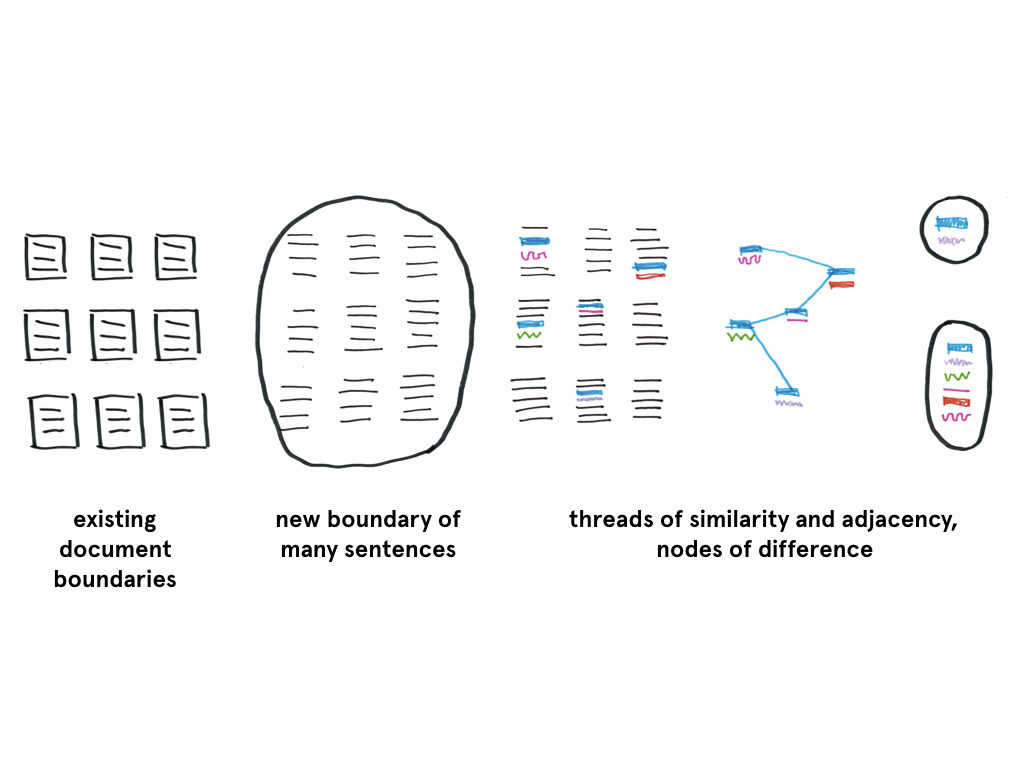
Much of my effort for this project focused on the how to create the structure for these relationships to come about.

To dismantle the existing boundaries and draw new ones is fundamentally a question of how it is organized in the database, meaning a focus on what properties do objects need to have and how can these properties be used?

Before processing the body of text, I crafted a spreadsheet to track which properties were inherited or unique and content or context related. For example, context included the IDs of adjacent sentences, whether the sentence was part of a duplicate document, and its relative position within a document.
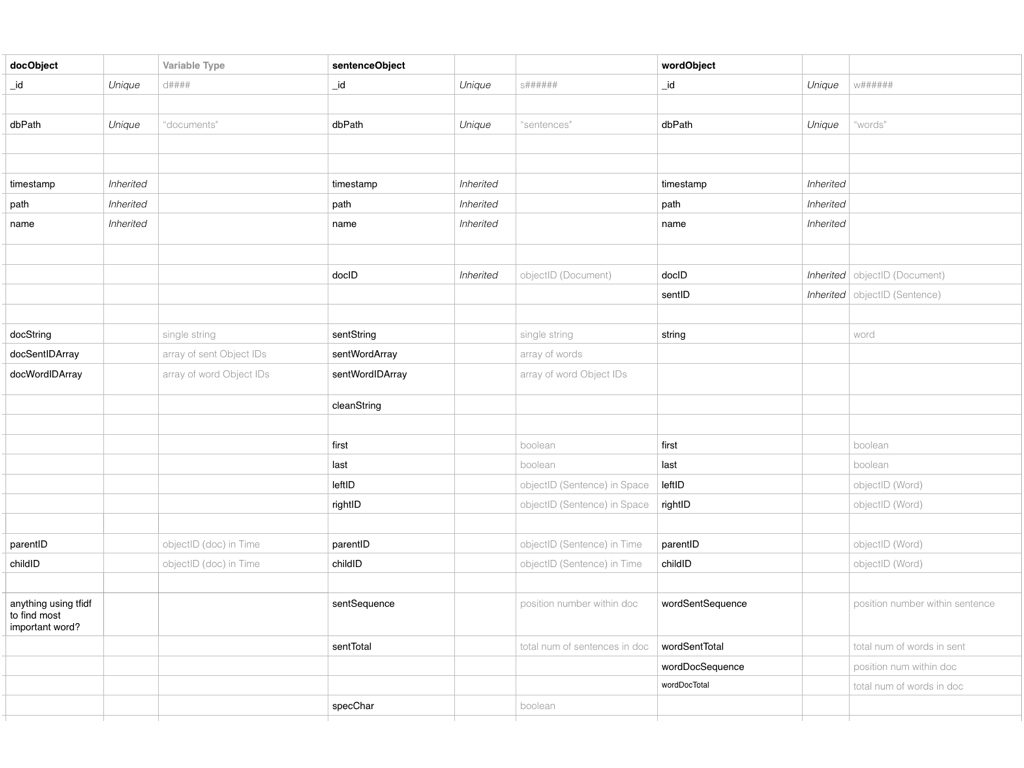
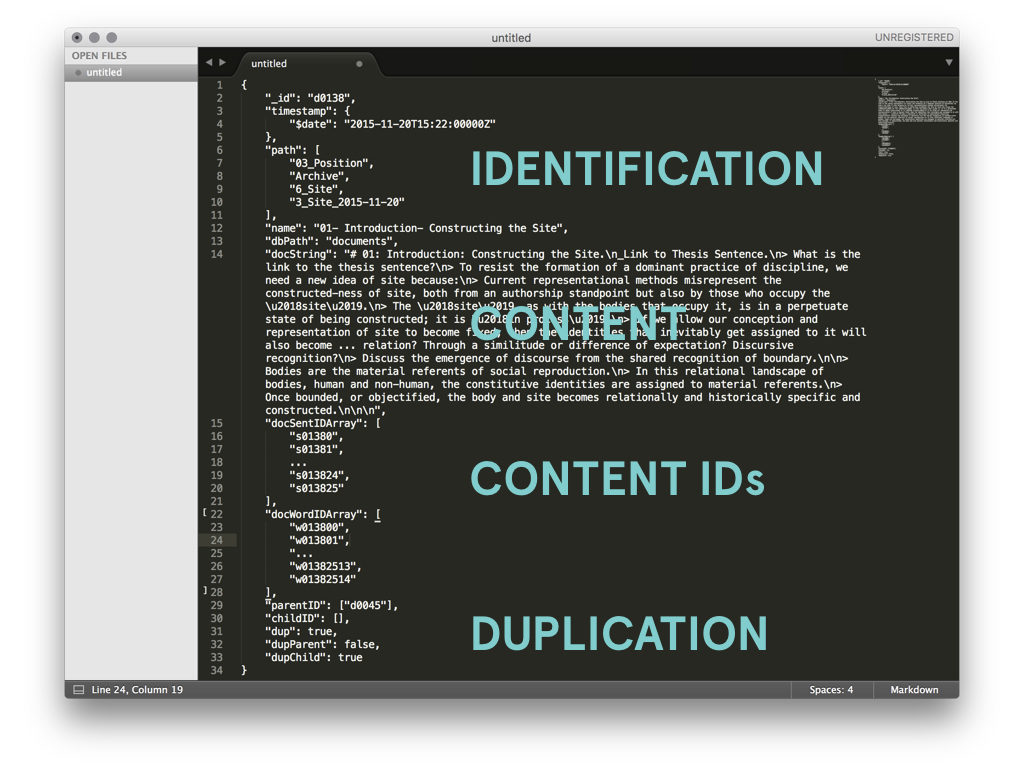
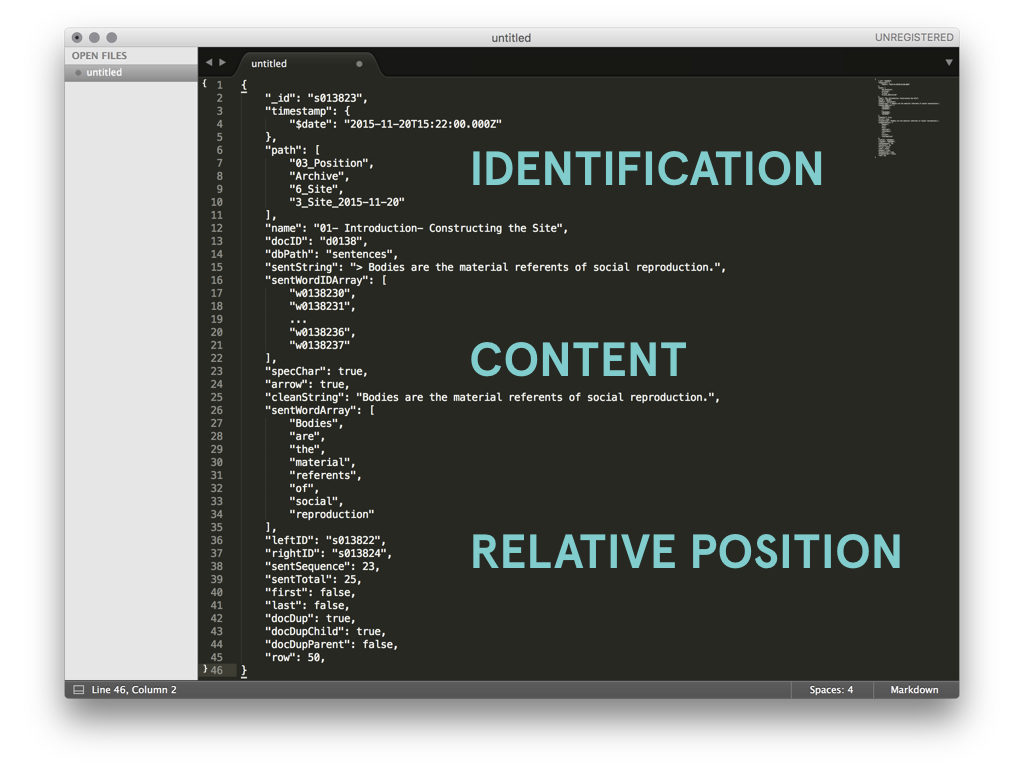
Once all the text had been atomized into the database collections, my focus shifted to how to compare the similarity of sentences. Similarity between sentences across time is the building block for identifying the dominant tendancies within the text.
After running into memory and time problems while attempting to compare every sentence to every other sentence, I moved to a comparison method in line with my ambitions for representation. Sentences were grouped into rows with each row representing a single date. The sentences in one row are compared only to those in follow four rows. This limits the number of comparisons while still recognizing that an appropriate match may not be in the immediately adjacent time period.
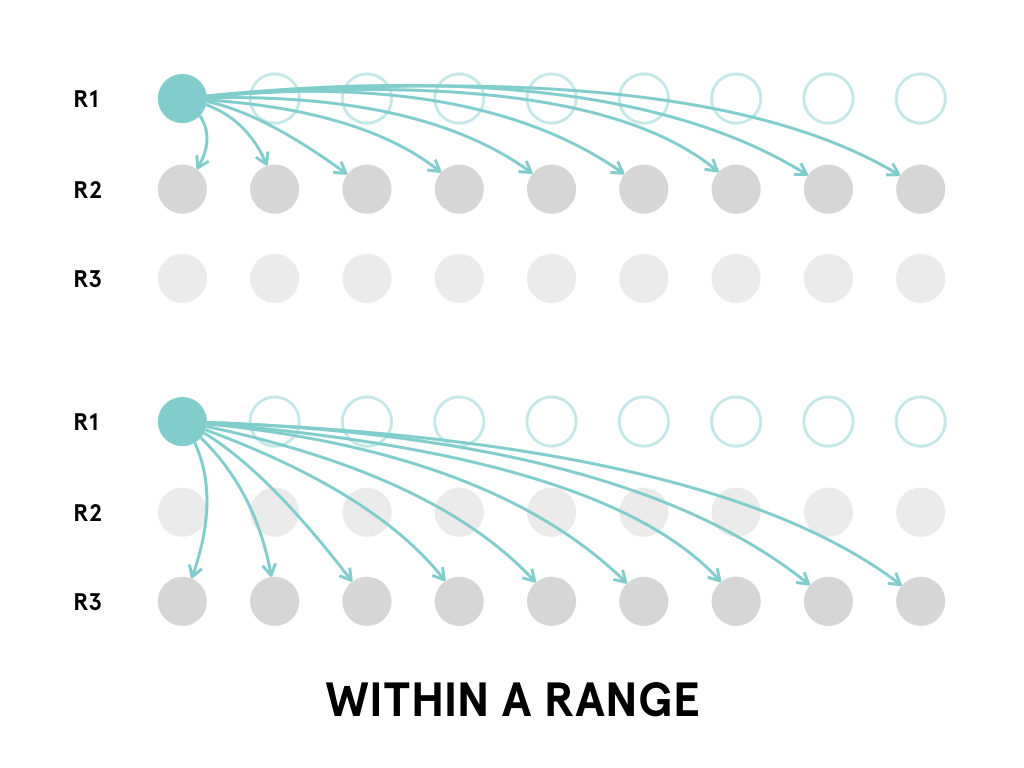
This comparison data was stored in a separate collection from the sentence objects themselves.

Difficulty with string comparisons….


‘How Thrilling’ uses the familiar song and dance of Michael Jackson’s “Thriller” to explore how technology can extend the body into many disparate spaces, through many representations, and for many audiences. Through this lens, the project examines how technology standardizes the body.
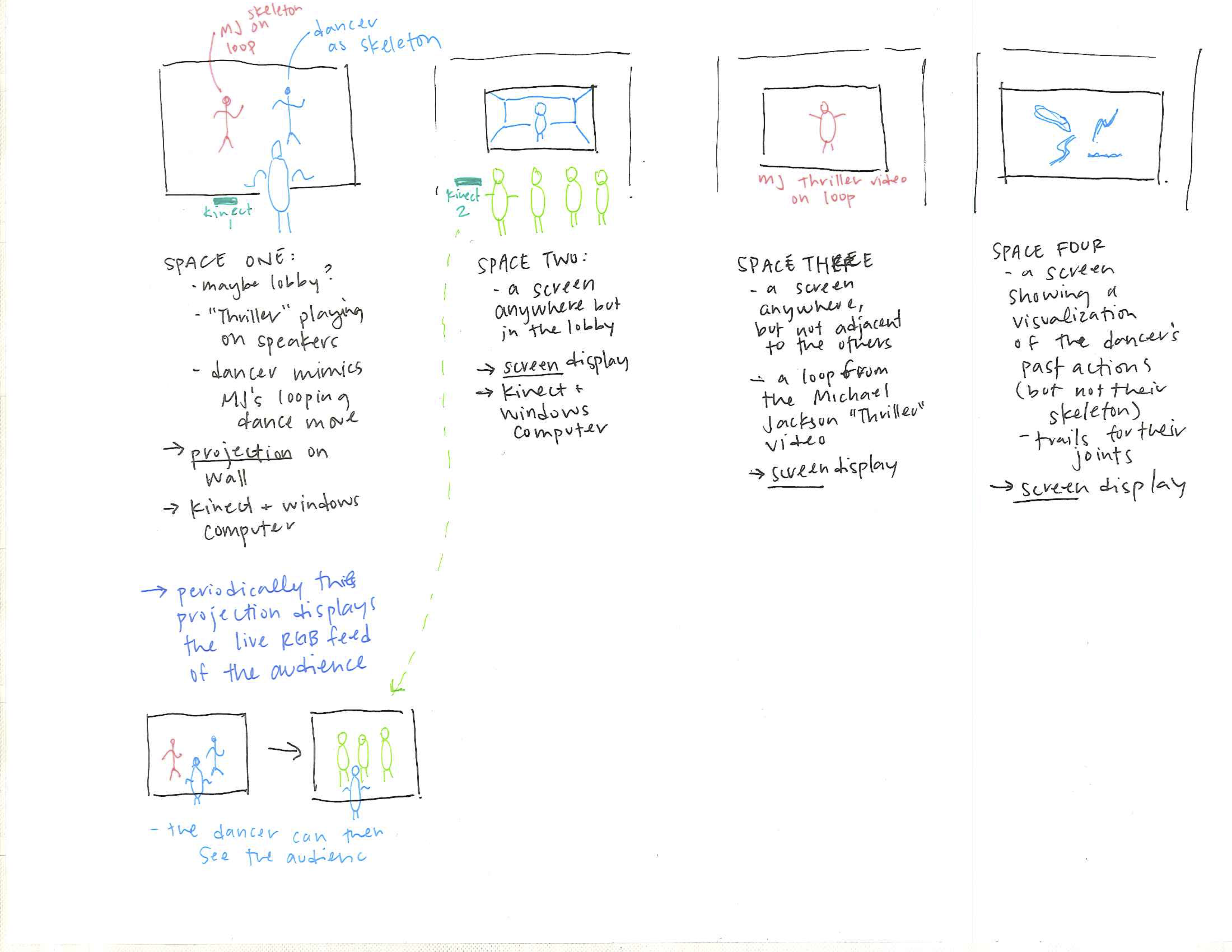
The project is composed of four feeds illustrated in the image above.
The performing body is presented through two primary representations in feed 1 and 2 respectively: an abstracted stick-figure-like skeleton that is normalized to a single set of proportions and an unmodified in-situ RGB image feed. The abstraction encourages an unselfconciousness of the performer while also highlighting its irregularity of motion in contrast to the precise repetition of Michael Jackson’s looping skeleton. In juxtaposition, the RGB feed–seen only by an audience in an entirely separate space without the accompanying music–highlights the nonconformity of bodies to any form of standardization.
If the performing body closely matches Michael Jackson’s moves or a set time period expires (whichever happens first), the front projection for the performer switches to reveal a live RGB image feed of the audience watching their RGB image feed. For a brief moment, they can communicate across these displays (basically just like Skype, Facetime, etc.) and the audience realizes they are not watching a recording by a live performance. Then, without warning, the projection for the performer reverts back to the abstracted skeletons.
Two additional feeds provide context within the project. Firstly, a constant silent loop of the original Thriller video excerpt gives visual context to the audience watching the RGB image of the performer. They might recognize the actions of the performer in the Michael Jackson video and vice versa. The last feed visualizes the motion trails of the performing body. Without the skeleton, it draws attention to the impercision of our actions despite attempting repetation.
Desired locations:
Since processing the text documents, I’ve been refining the goal of “finding latent (content and contextual) relationships within a large corpus of texts”. As the text remains a work in progress, I want to focus on how it has evolved and continues to evolve. A genealogical approach to text-relationships can be used to identify what pieces have been disregarded or ignored (and thus require further inspection) or identify the dominant tendancies and trains of thought.
Beyond looking at the past, I think this project can provide a foundation for developing a writing tool that moves beyond version control or collaborative commenting. Version control tends to provide a fine-grain binary approach: it compares two things and extracts the insertions or deletions. While this is helpful in an isolated scenario, I’m interested in broader developments across multiple objects over many time periods. Alternatively, version control also provides a high-level view indicating change-points over a long time, but those points of change are overly simplified – often represented by just a single dot. Without context or without knowing what specific time a change was made, this larger overview provides little information beyond the quantity and frequence of changes. Through a geneological and contextual approach to analyzing an existing body of text, I’m hoping to identify what sort of relationships could inform the writing and editing process.
With all the data now added to the database, I’ve been exploring sentence similarity. The diagram below shows the process I’ve gone through up to this point.
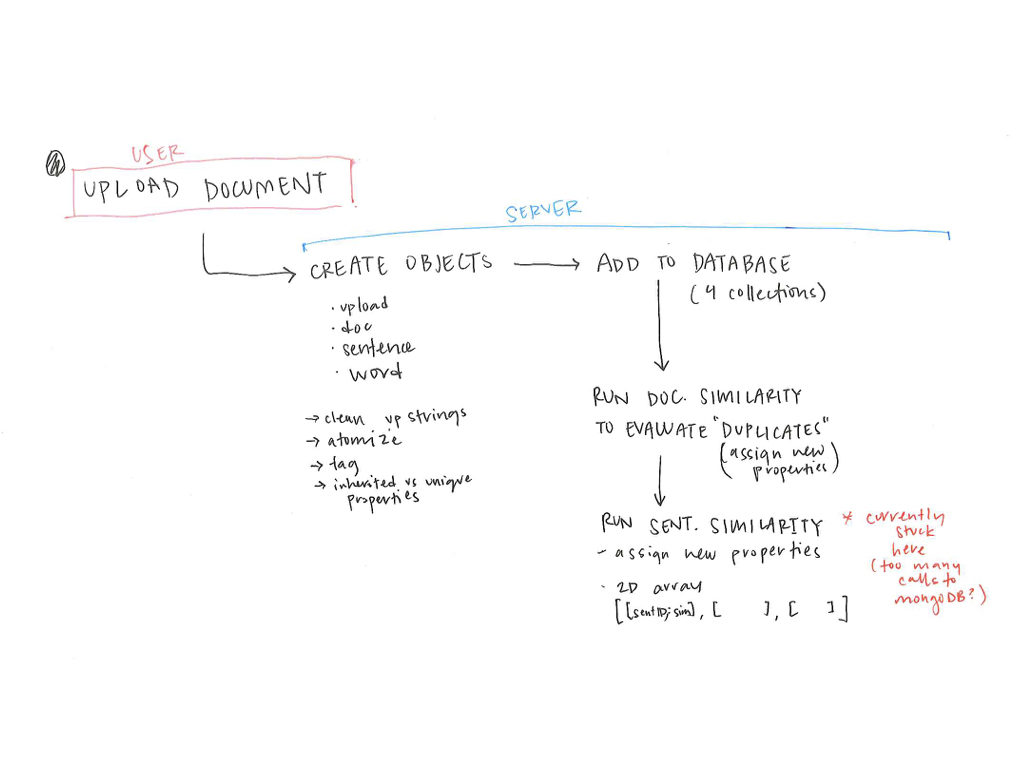
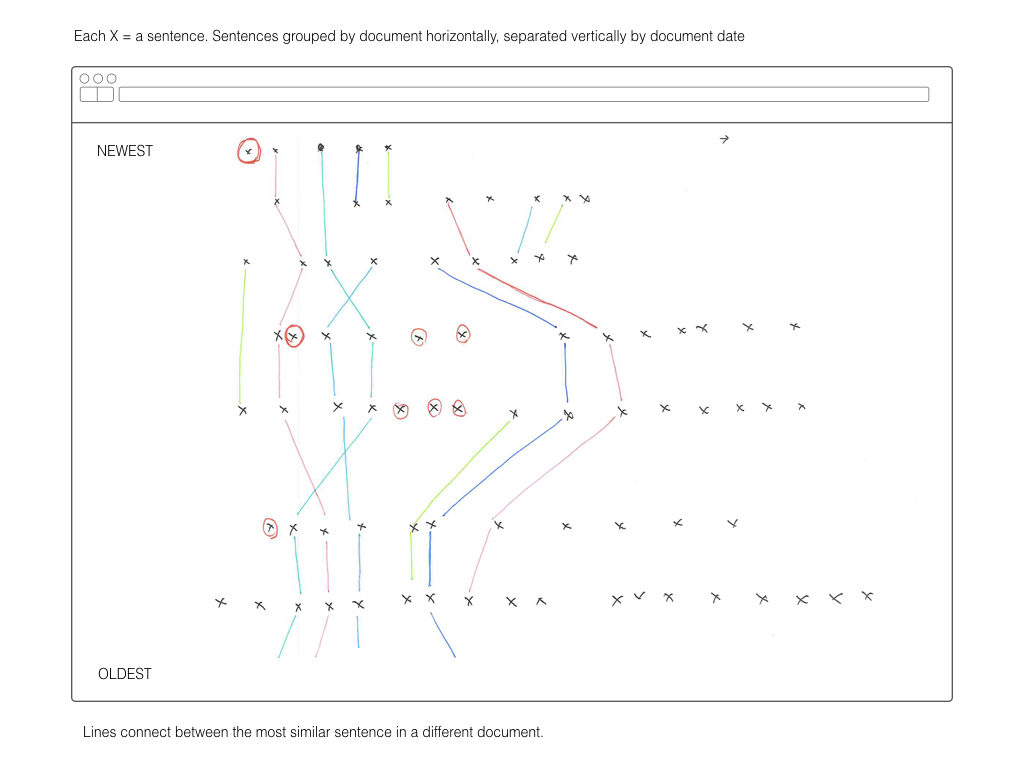
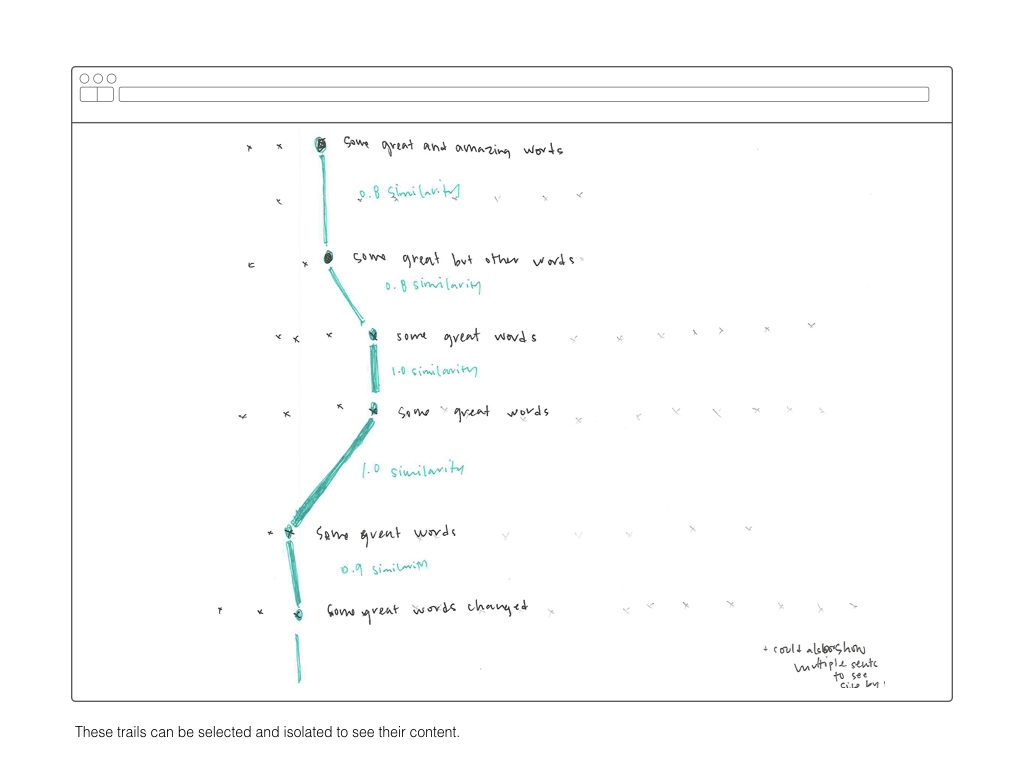
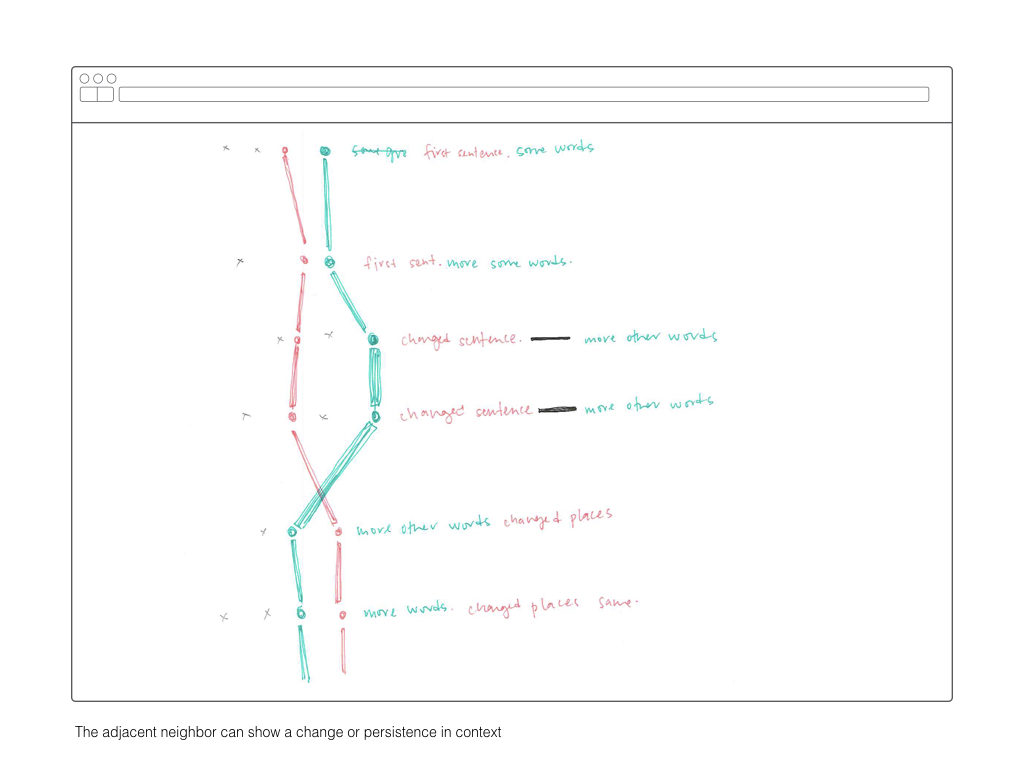
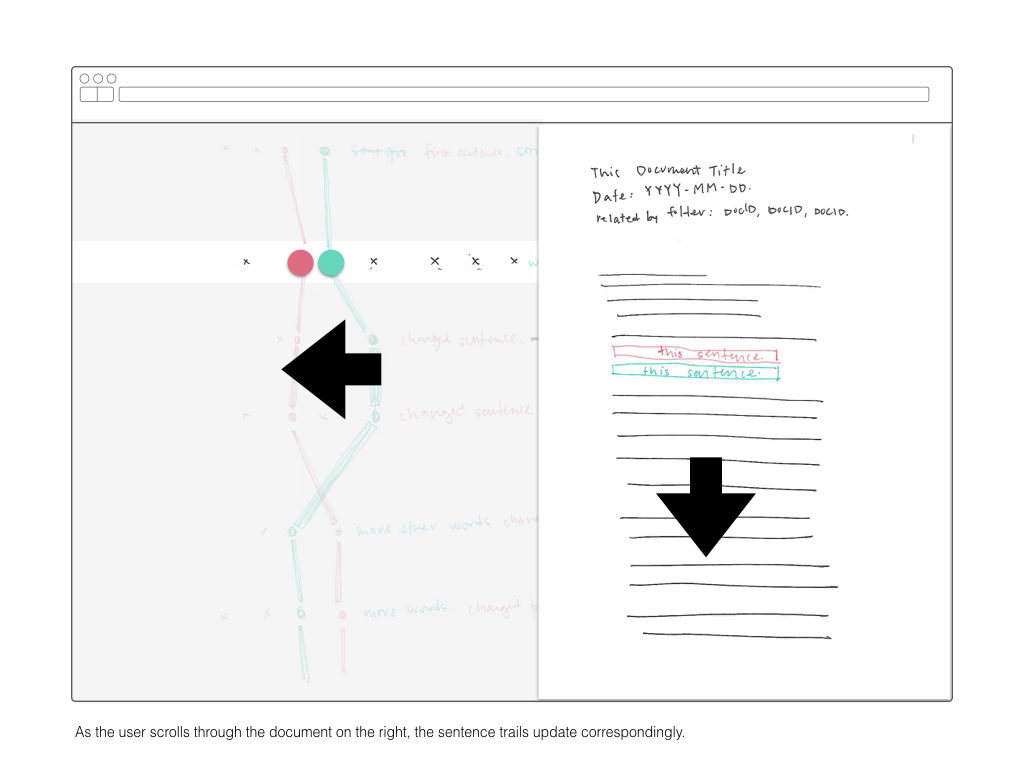
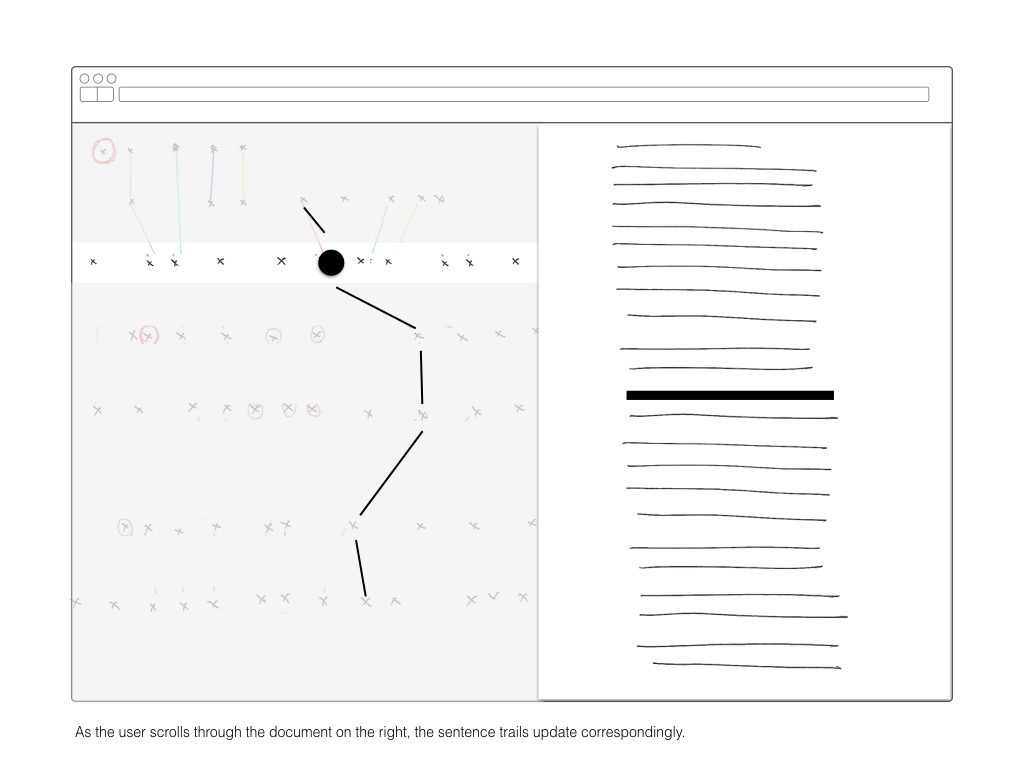
Once I’ve computed a two-dimensional array mapping the similarity of all sentences to each other, I plan on using that information to create visual interface for explore those relationships. The wireframes below are a rough sketch of what form this might take.
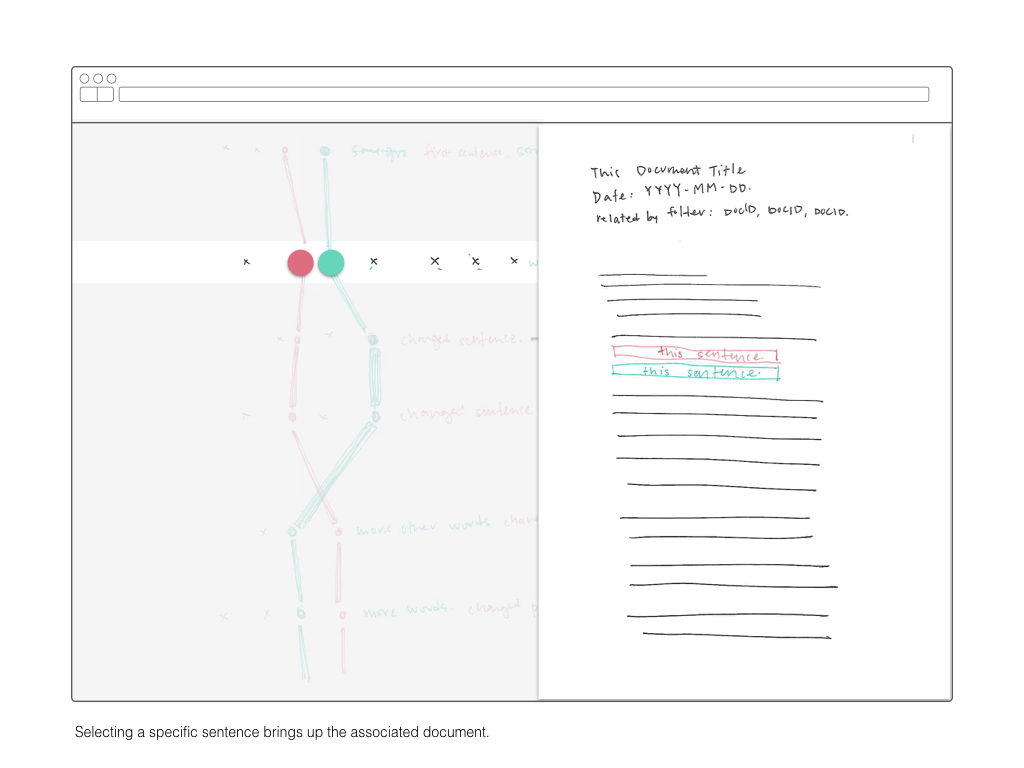
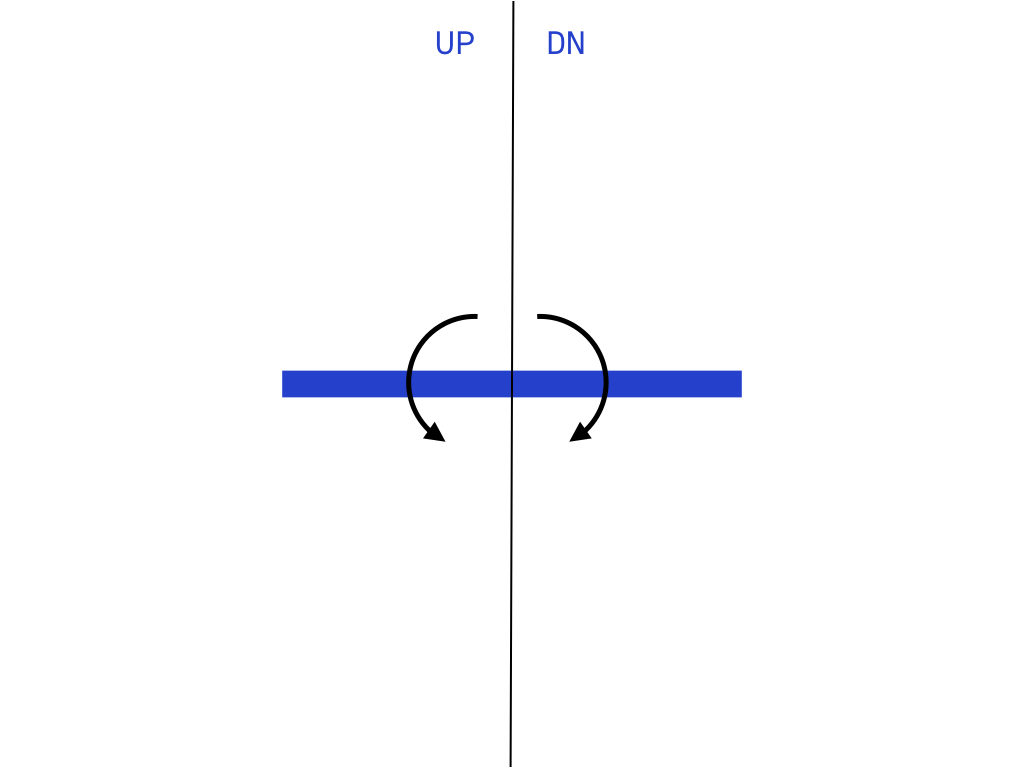
The lastest controller for Pong uses a cardboard plane attached to a potentiometer to control both speed and direction of the virtual paddle. The rotation of the potentiometer divided in half to control direction, and then within that extent, speed is modulated.
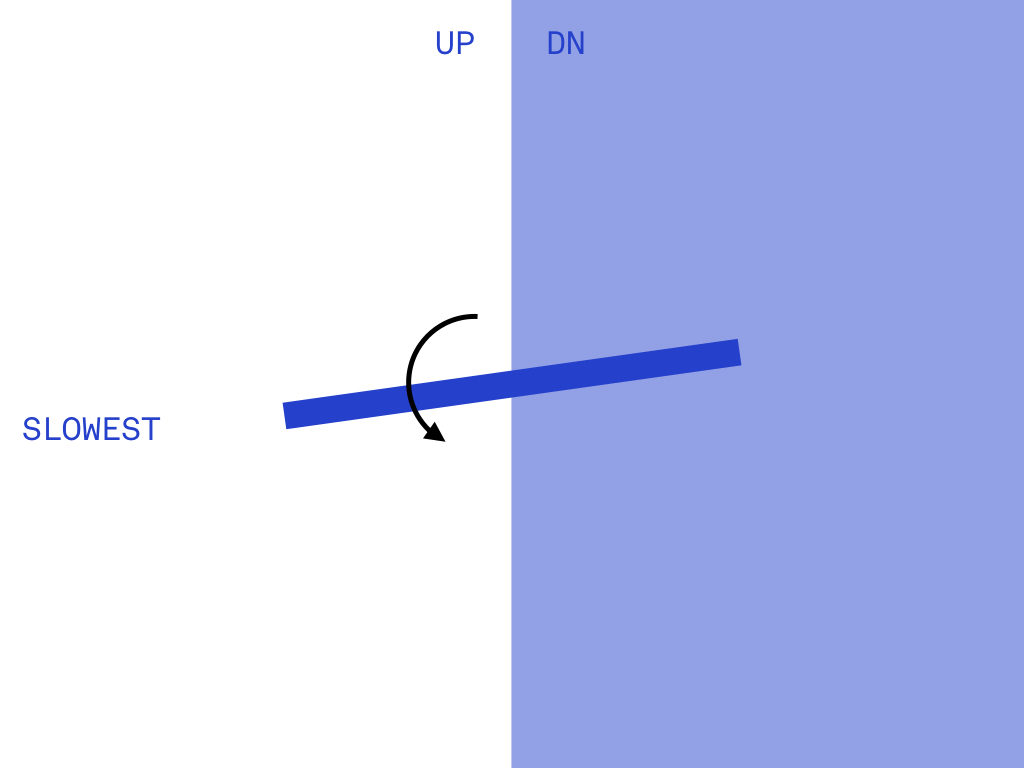
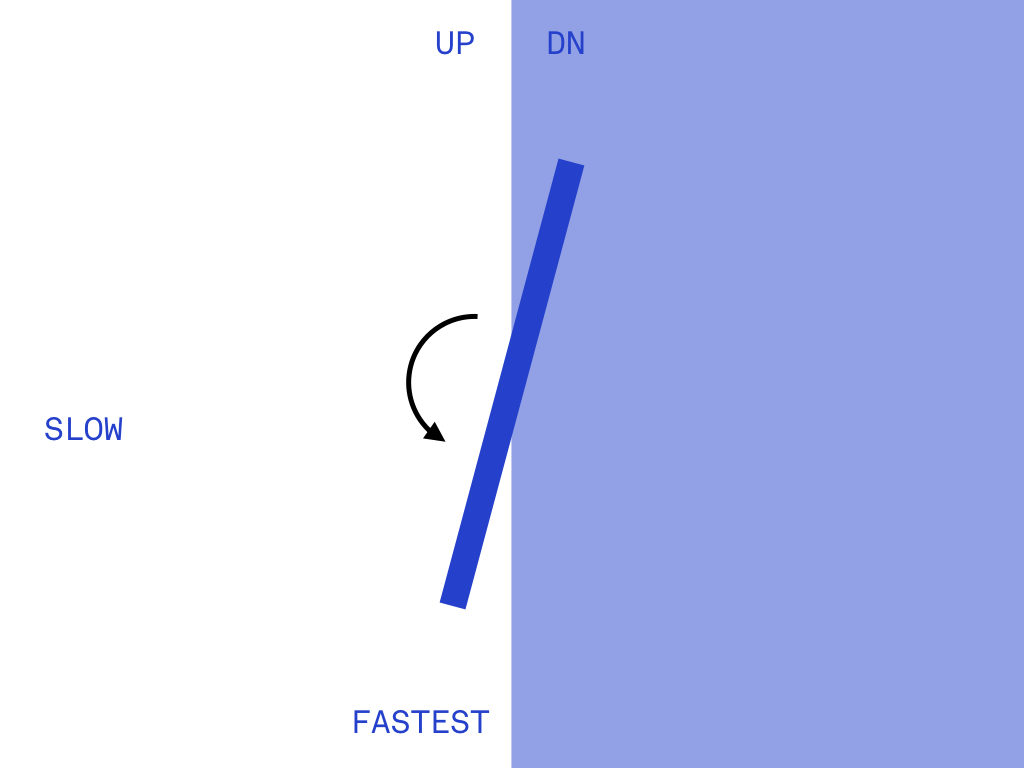
Process
Because the ESP Chip is somewhat expensive (relatively), I invested in protyping my circuit on breadboards and milled boards on to which the chip could plug in temporarily.


In order to prototype directly with the chip rather than a breakout board, I needed a programming jig for connecting via USB and closing certain routes on particular pins. When programming…

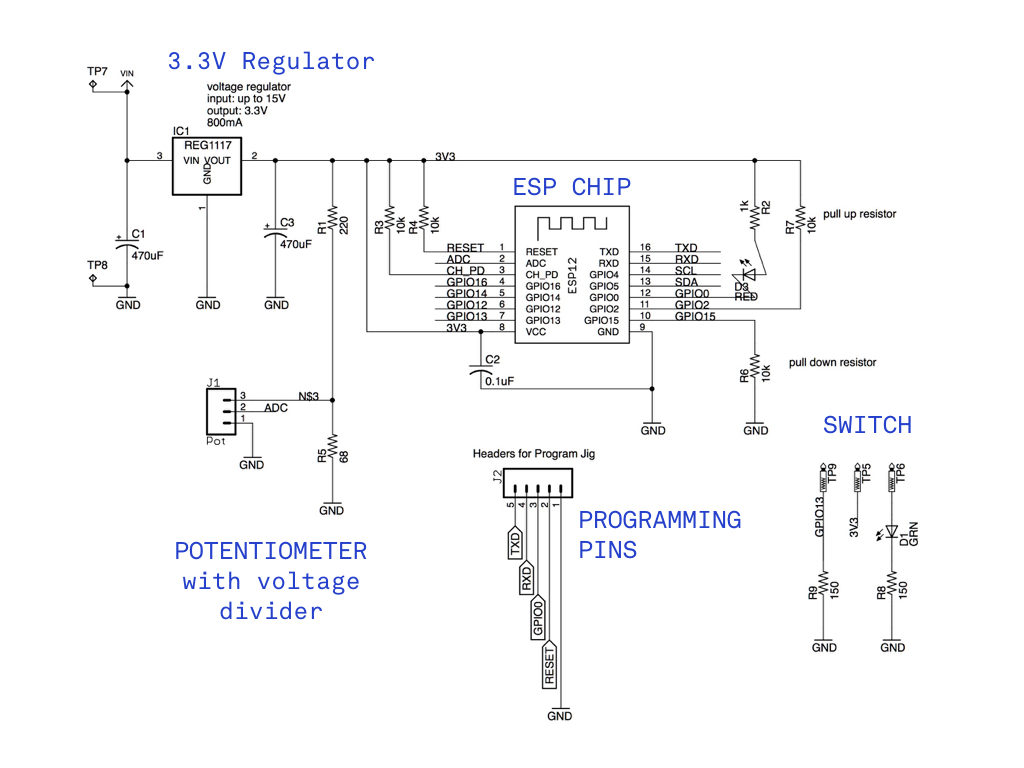
The Board
The ESP chip draws a significant amount of power; however, conflicting advice online made it difficult to size capacitors. Although, I found these tips to be most helpful. While they recommend a very large capacitor (470 uF) across the Vcc to Gnd, the Adafruit breakout only used 10 uF. While I included two 470 uF capacitors, my next iteration would explore smaller size. However, a 0.1 uF decoupling capacitor across the ESP8266 Vcc to Gnd inputs very close to the pins was a critical addition.