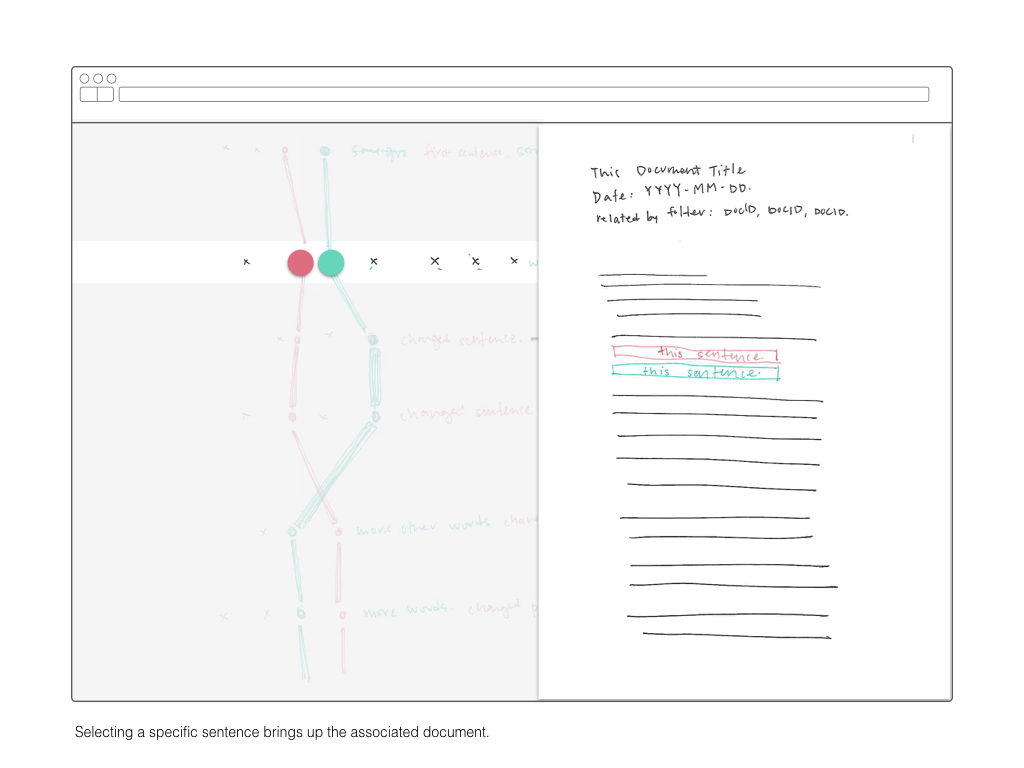
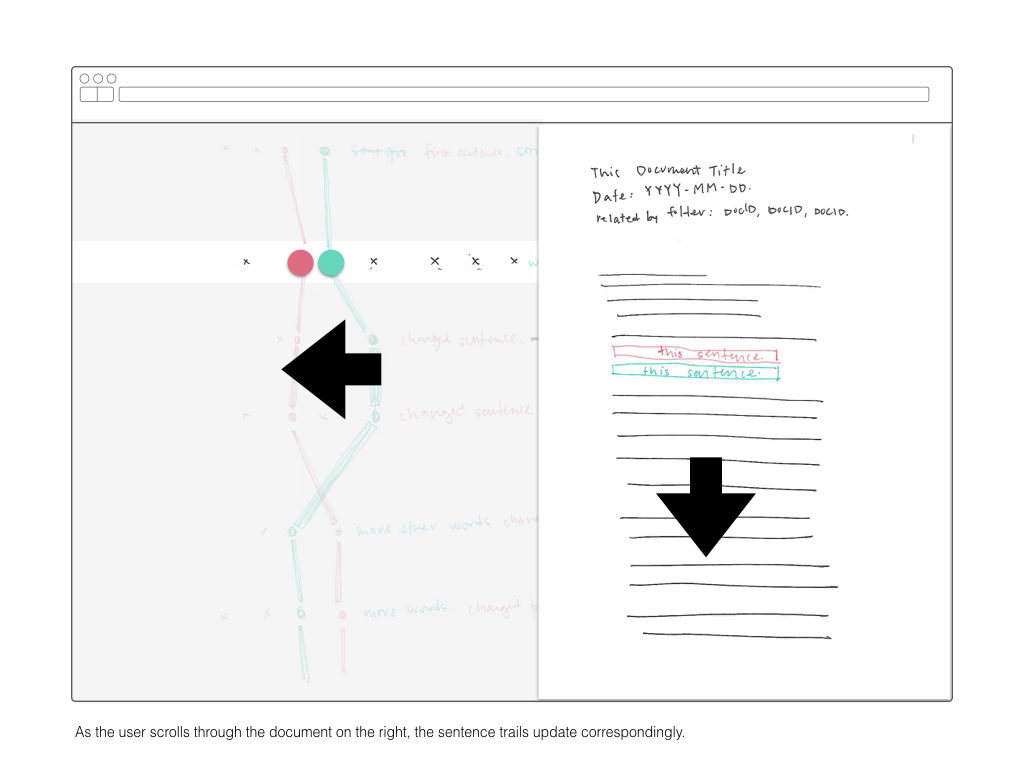
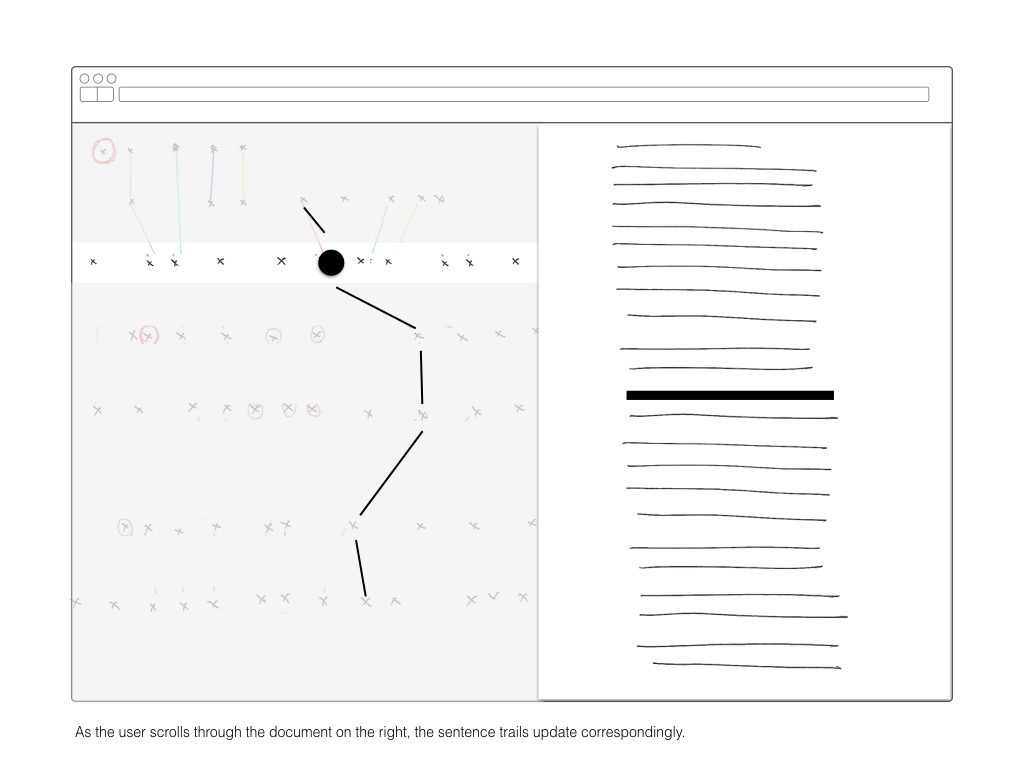
As I’ve discussed in previous posts, this project attempts to find relationships of dominant tenancies and abandon nodes within a large body of text. The large collection of text evolved in structure over time, thus examining at from a purely document-based approach is not appropriate.
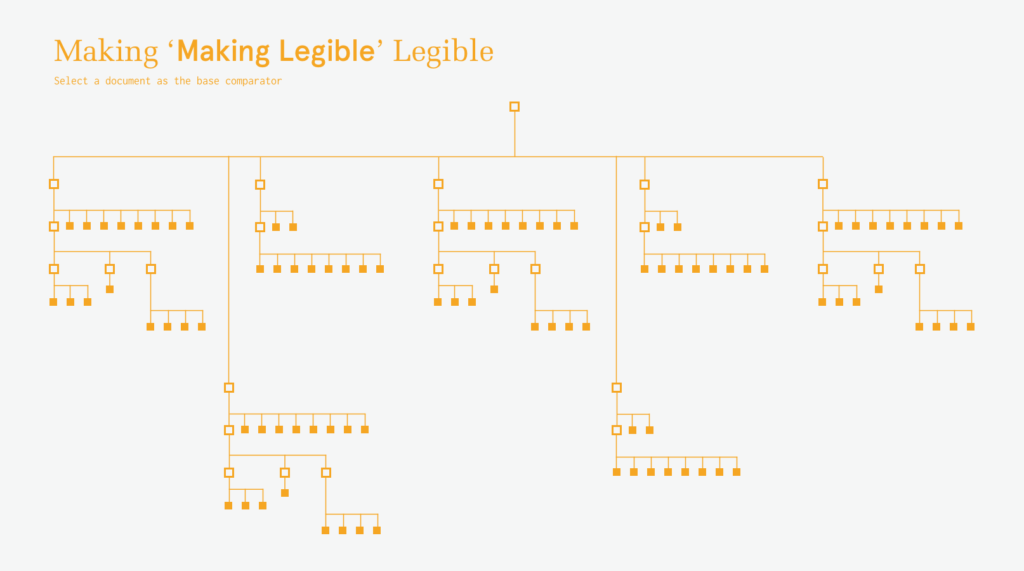
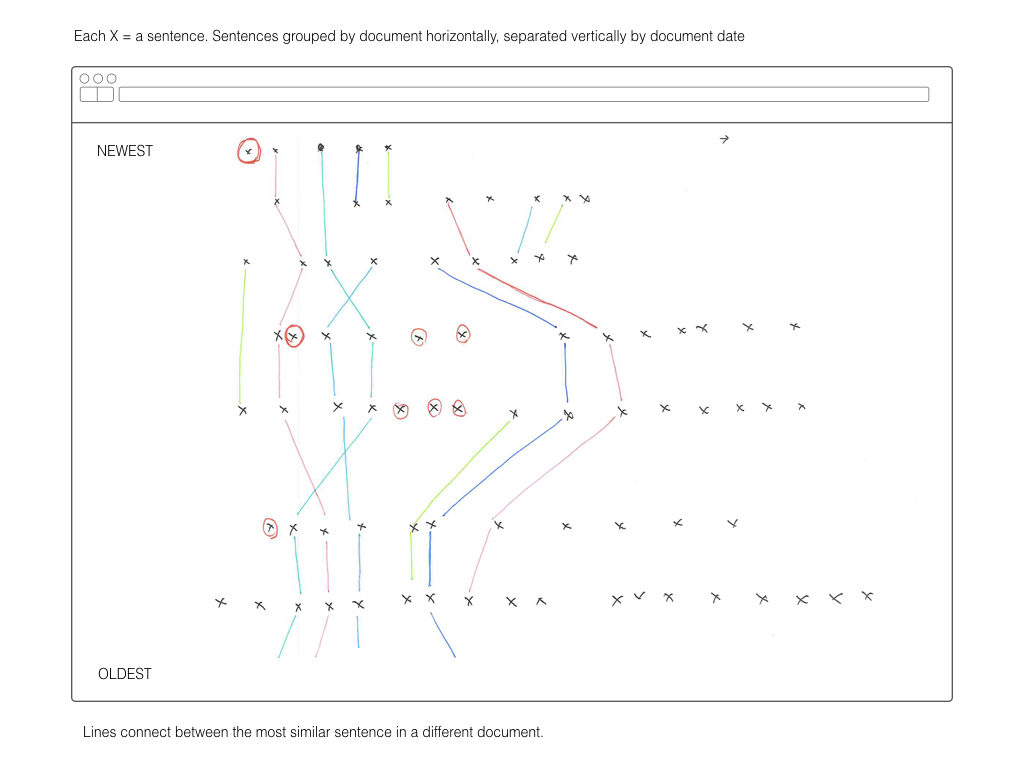
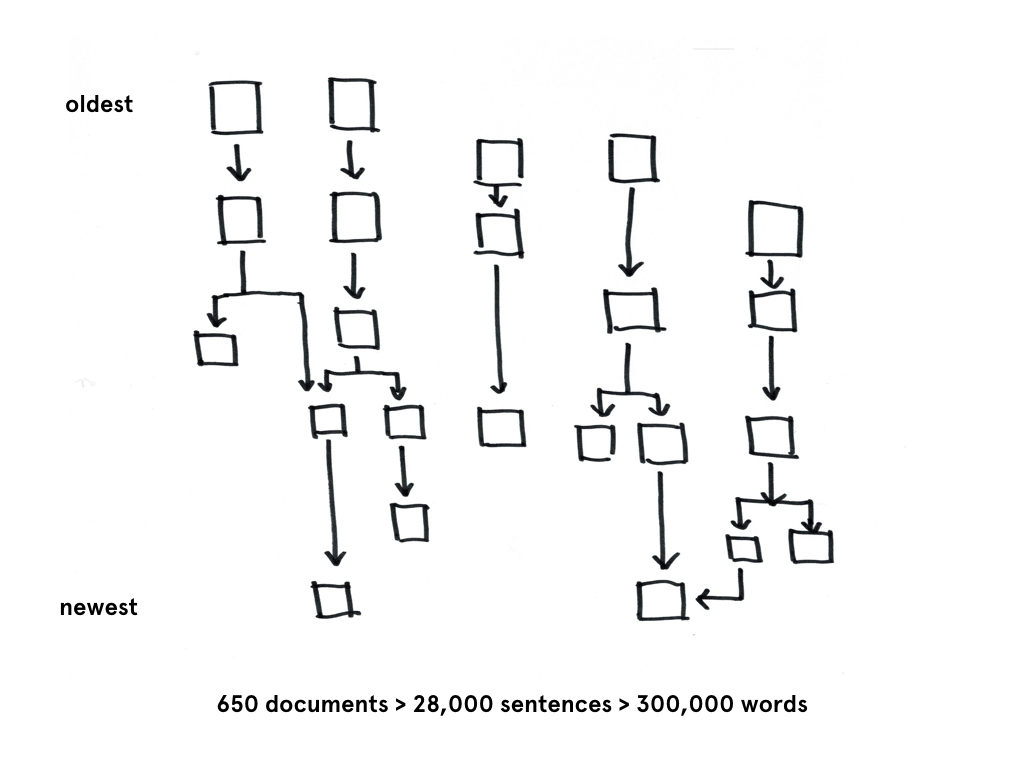 If the existing boundaries of a body of text are conventionally documents, this projects instead treats sentences as the primary object and attempts to draws new boundaries around sentences in various documents.
If the existing boundaries of a body of text are conventionally documents, this projects instead treats sentences as the primary object and attempts to draws new boundaries around sentences in various documents.
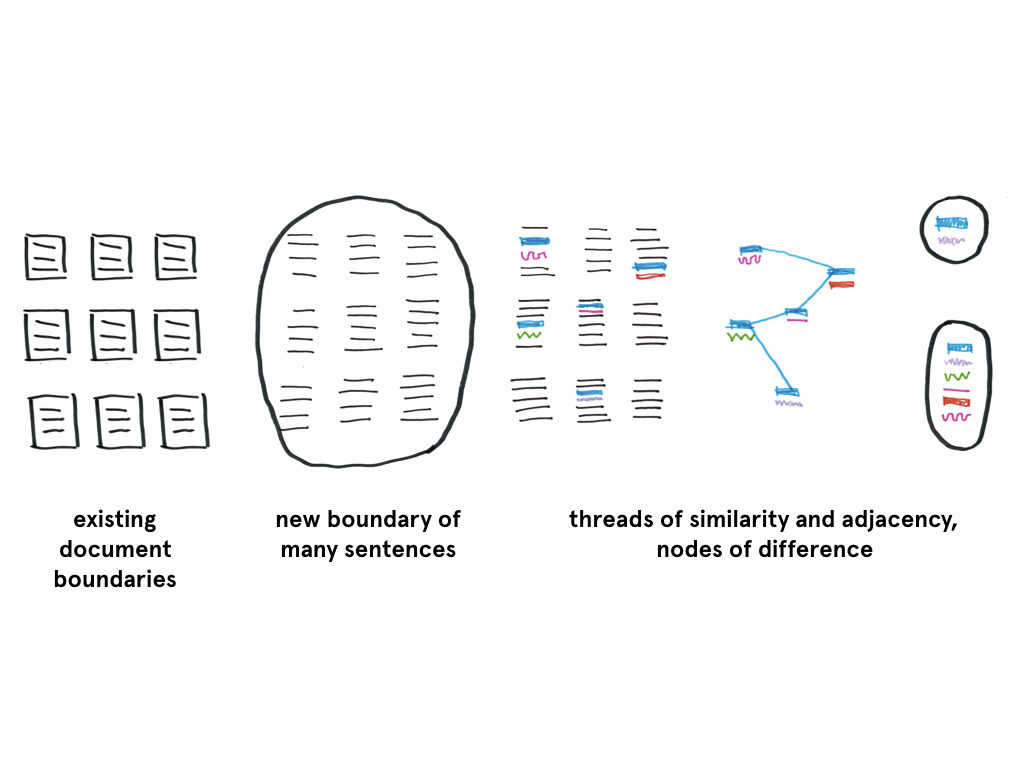
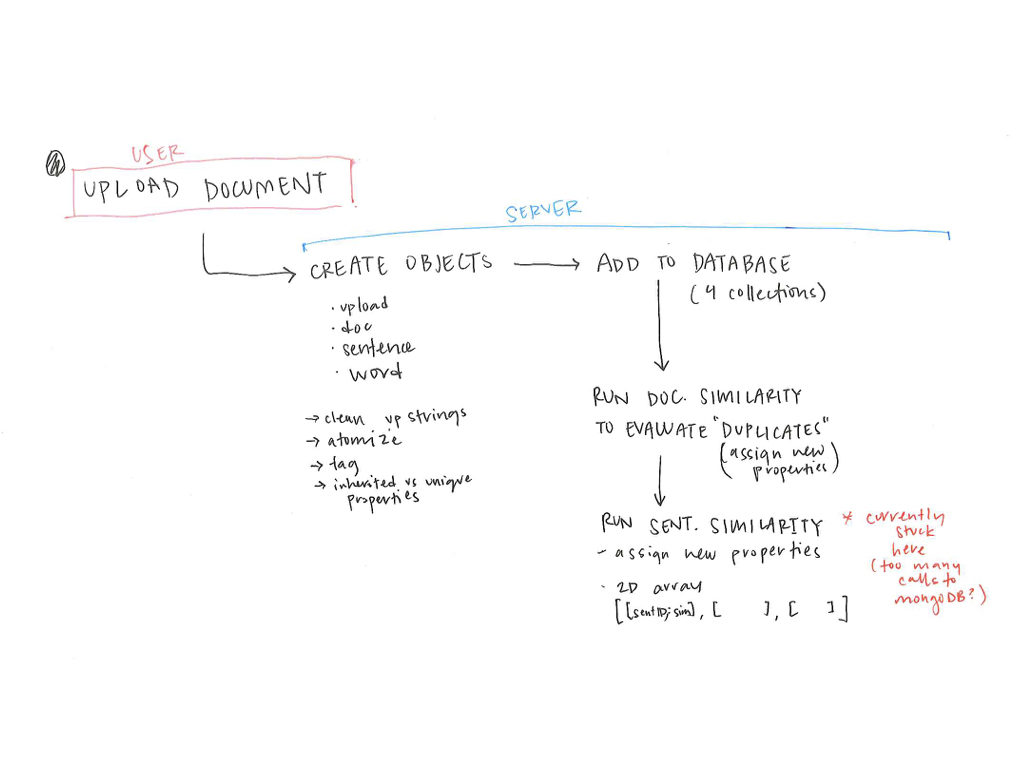
Much of my effort for this project focused on the how to create the structure for these relationships to come about.

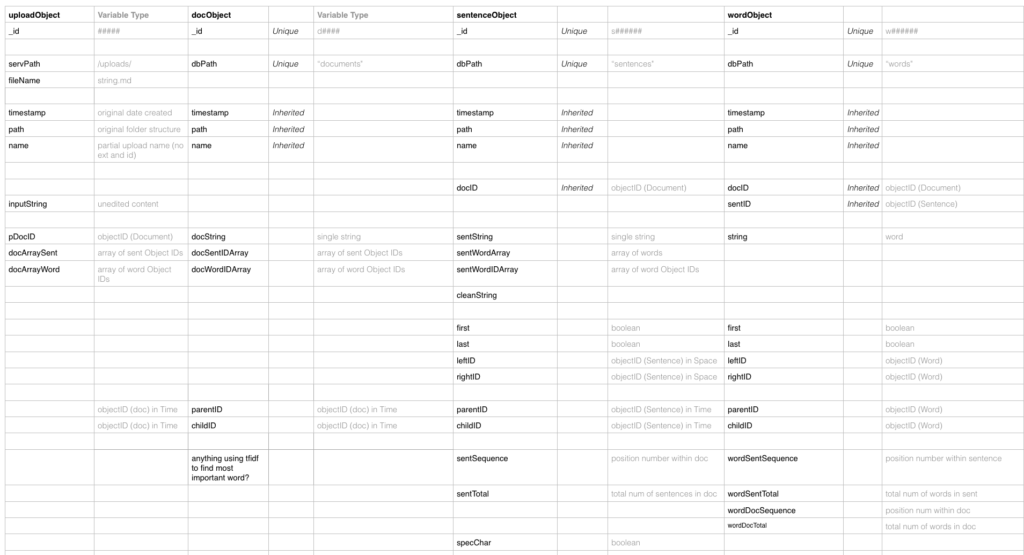
To dismantle the existing boundaries and draw new ones is fundamentally a question of how it is organized in the database, meaning a focus on what properties do objects need to have and how can these properties be used?

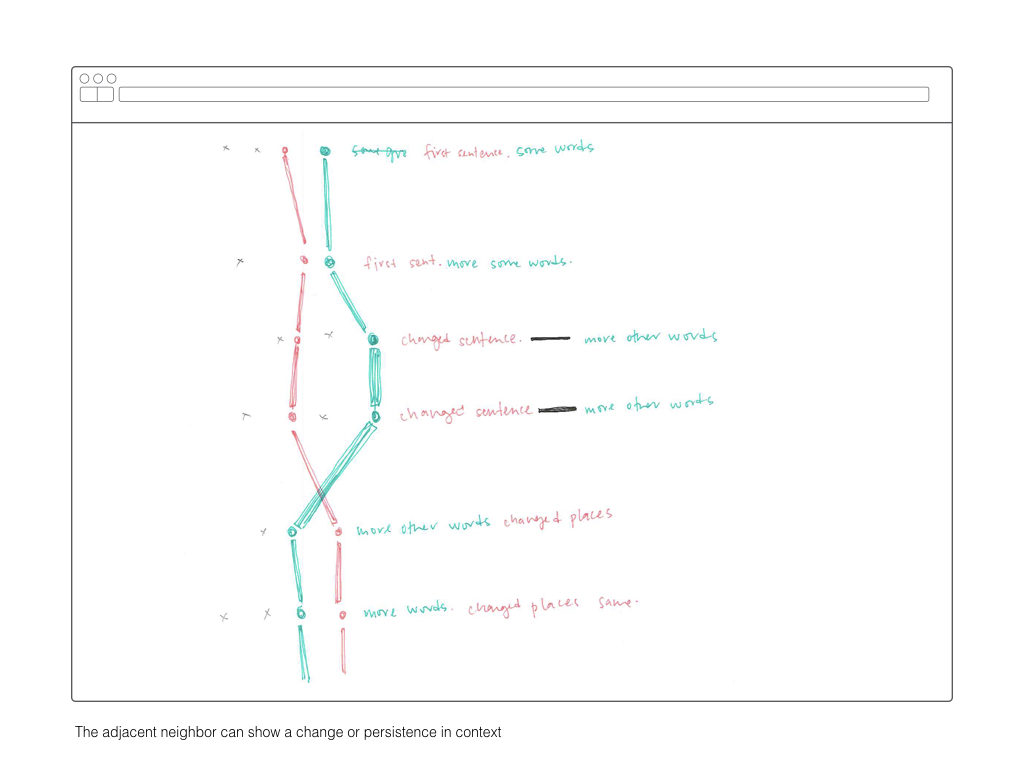
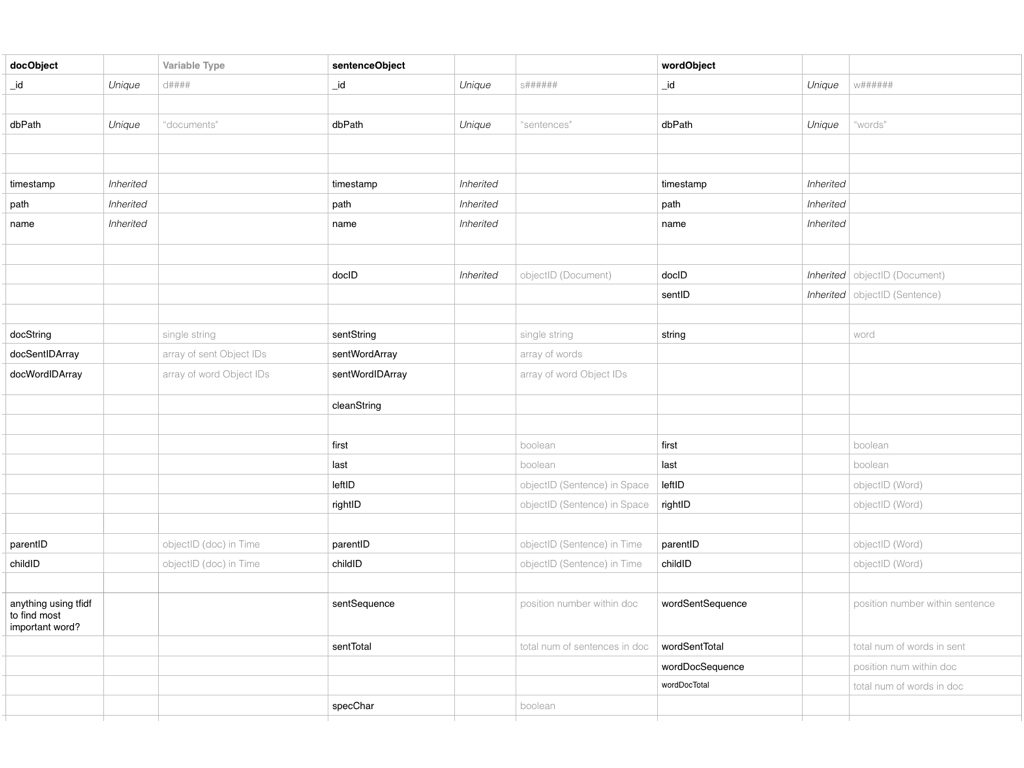
Before processing the body of text, I crafted a spreadsheet to track which properties were inherited or unique and content or context related. For example, context included the IDs of adjacent sentences, whether the sentence was part of a duplicate document, and its relative position within a document.
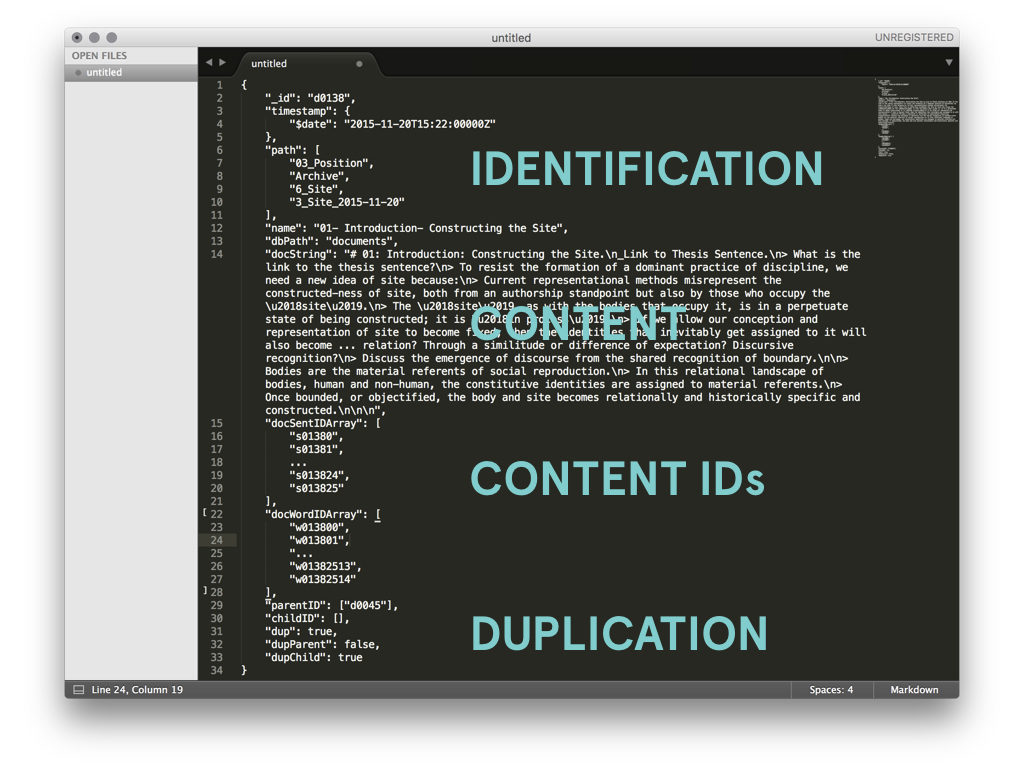
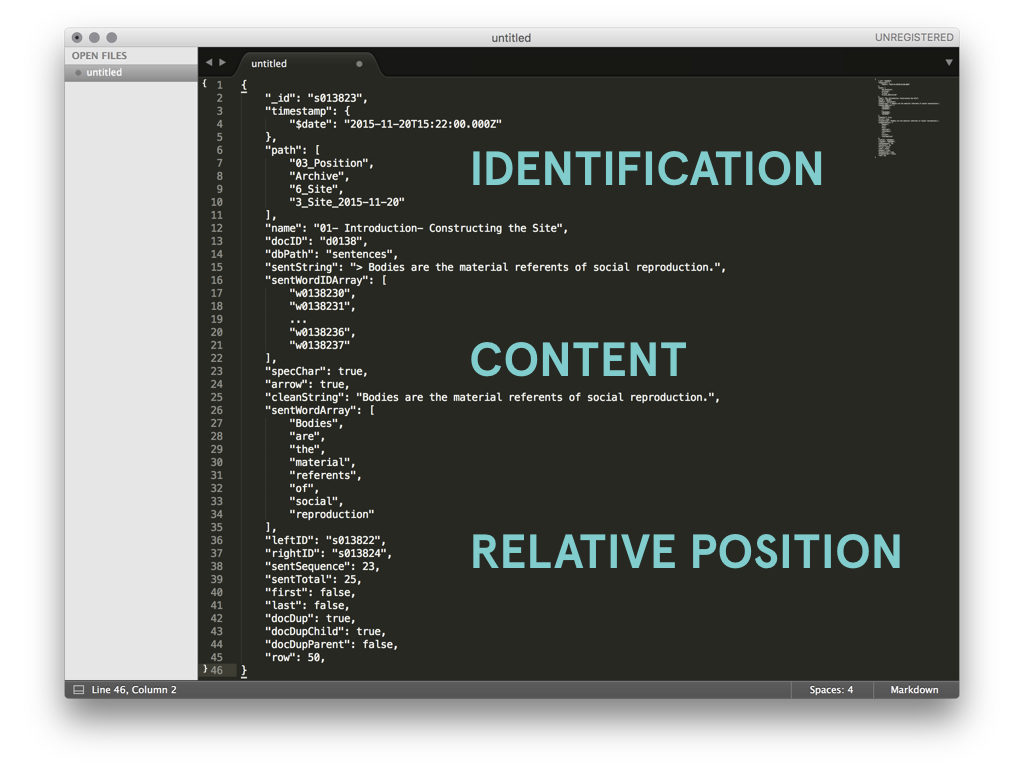
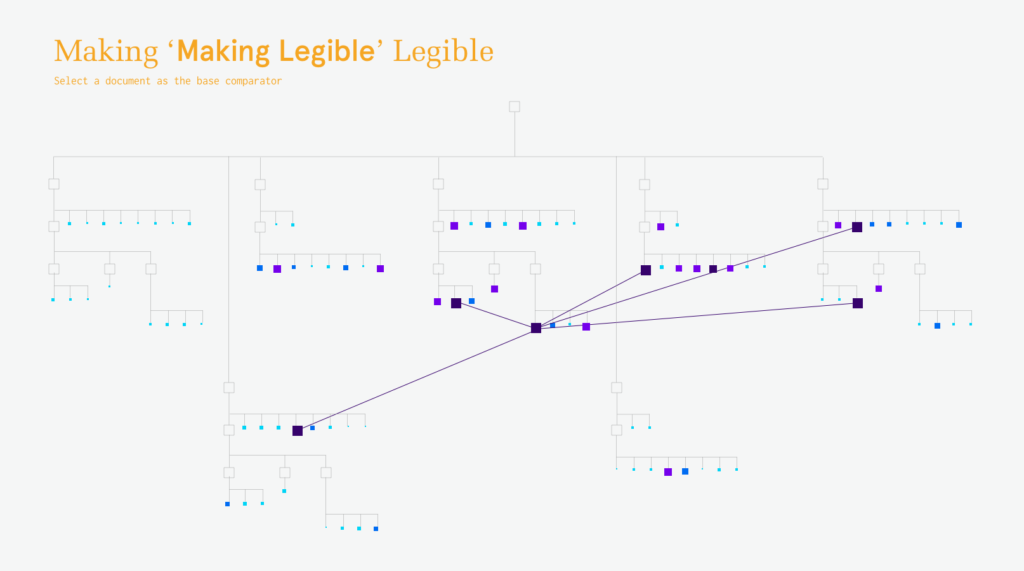
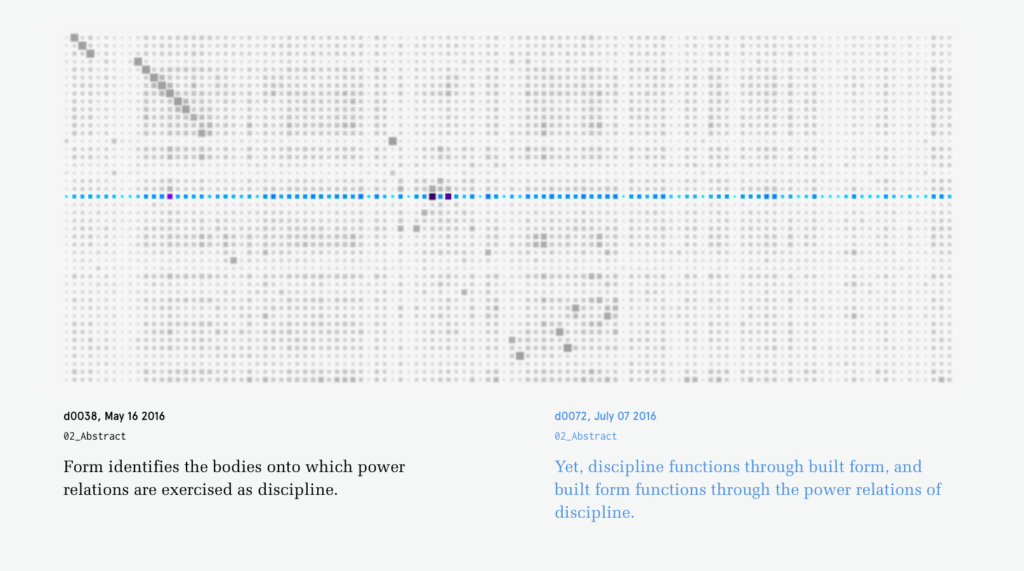
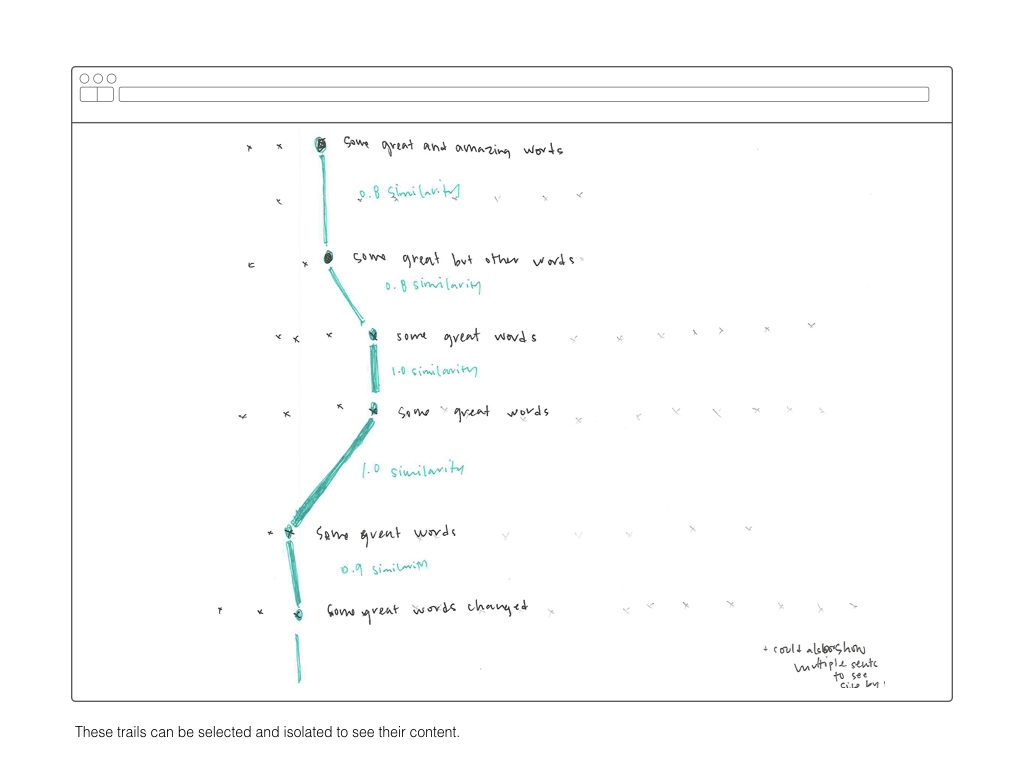
Once all the text had been atomized into the database collections, my focus shifted to how to compare the similarity of sentences. Similarity between sentences across time is the building block for identifying the dominant tendancies within the text.
After running into memory and time problems while attempting to compare every sentence to every other sentence, I moved to a comparison method in line with my ambitions for representation. Sentences were grouped into rows with each row representing a single date. The sentences in one row are compared only to those in follow four rows. This limits the number of comparisons while still recognizing that an appropriate match may not be in the immediately adjacent time period.
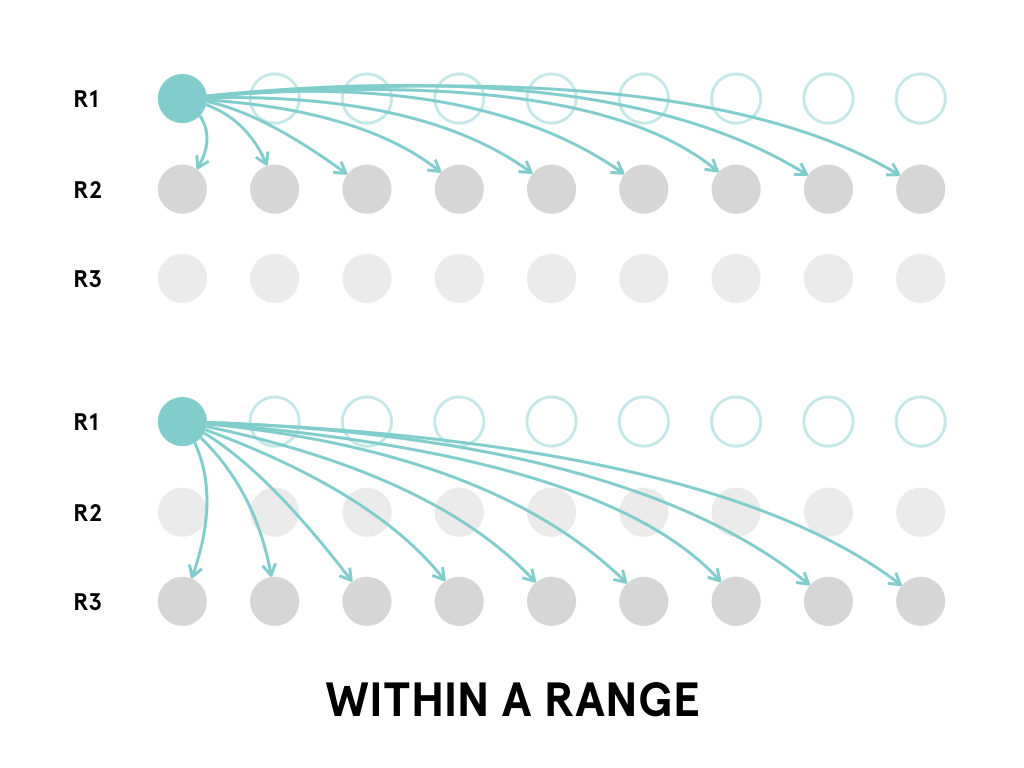
This comparison data was stored in a separate collection from the sentence objects themselves.

Difficulty with string comparisons….