Brainstorming
I had a number of ideas for this spatially-oriented data art project that I wanted to test before narrowing it down to one.
Invisible Cities
An installation of platonic oversized forms create an abstract environment to hear Italo Calvino’s “Invisible Cities”. As with many museum and gallery experiences, an indivdual audio tour device is available. Audio clips play based on an individual’s position relative to others, the objects and empty space. Each ‘hot spot’ is associated with different clips from the text. Depending on how each person circulates through the environment and their latent interation with others, each could hear potentially a different ordering of clips. With this lack of specific order, each listener constructs their own invisible city from Calvino’s text. The video below demonstrates the concept from a planametric view, and uses left and right speakers to distinguish the tracks heard by different individuals. Listen with just the left, then just the right, then both to get a sense of various experiences. The audio is sourced from Calvino’s reading of Invisible Cities in 1983 92nd St Y.
Trace-Route Search Enginge
Building on an earlier project in Understanding Networks, I was interested in exposing the physical locations of IP address hops that every request makes before a webpage is delievered. Rather than enter a particular website address into the browser bar, this is taken as an input, and each hop is shown with the corresponding Google Streetview. If an individual continually uses this service for navigating to all websites, they might start to notice patterns in routing, particularly in the initial hops as well as identify differences even when navigating to a frequent page. A couple things to further explore is incorporating a map view and making it “hang time” at a particular location more clear. I used beeps to indicate the beginning of a hop, but when a response takes longer than expected, the silence comes across ambigulously — is it broken or just waiting? Additional, it would be interesting to see if a browser extension could be used to implement the same experinece when clicking on links on a page, rather than directly inputting a destination.
Broadcast 2.0
Broadcast is also a previous project I keep coming back to and am never satisfied with. The basic premise is to use proximity between two individuals to prompt the swapping of whatever music they’re listening to at that moment. Although I’ve developed a prototype of it before, I briefly explored other interactions and how it might be implemented without a map view. The video below highlights a few of these iterations.
Project: Instagram-Directions Mashup
The idea I developed furthest in terms of technical implementation combined Instagram and directions-mapping. Given two locations, rather than returning the most optimal route, directions are routed to a number of popular Instagram destinations within a distance from the start and end points.
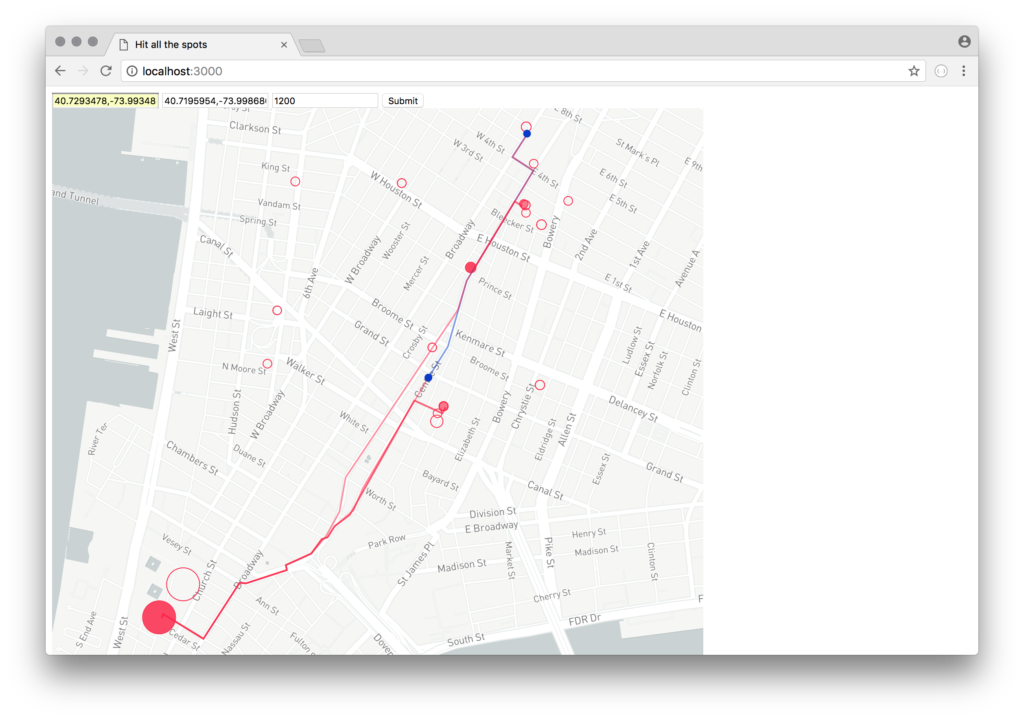
The service uses a number of different APIs to gather and process data.
1. Facebook Places API
When the user inputs two locations, this is processed through Facebook’s Places API to find nearby places as well as to get a “Facebook ID” for the particular locations. The method returns a paginated collection of any places within a particular distance (in meters) from the supplied location. I only used the first 25 places and excluded any that were categorized as ‘City’ or ‘Neighborhood’ as I’m looking for additional destinations. Below is a sample output of the JSON response.
"name": "New York City Halloween Parade",
"id": "142696759079705",
"location":
{
"city": "New York",
"country": "United States",
"latitude": 40.725358658563,
"longitude": -74.004135274659,
"state": "NY",
"street": "Spring Street and 6th Ave",
"zip": "10013"
},
"category_list": [
{
"id": "179943432047564",
"name": "Performance & Event Venue"
},
{
"id": "152880021441864",
"name": "Community Organization"
}]
}
Why Facebook’s API? I also looked at Foursquare’s API which has a similar endpoint for nearby places. Since the Instagram scraper module required a Facebook-specific ID, as a first draft it’s been easier to use the Facebook API. However, I’m interesting in seeing how different the results are between the two services. In particular because, when testing, I often found that specifying anything below 900m returned no results and wonder if Foursquare would produce the same limitation.
2. Insta-scraper
In 2016, Instagram locked down much of their API capabilities and minimized what type of applications could access the various endpoints. Fortunately, someone wrote a node module for scraping the public content and included a method searching based on Facebook’s location ID of the place. For the two collections of nearby places, I used the insta-scraper module to pull the most recent and most-liked photos for each location. It returns an extensive JSON object with links to the media file, counts, likes, caption, etc…I focused on the number of posts associated with a particular place (the “count” property) and the number of likes for the top post.
"id": "292808",
"name": "Aquagrill",
"has_public_page": true,
"lat": 40.7252575,
"lng": -74.0037043,
"slug": "aquagrill",
"media": {
"nodes": [
{
"comments_disabled": false,
"id": "1643746331771283727",
"dimensions":
{
"height": 830,
"width": 1080
},
"owner":
{
"id": "1017633131"
},
"thumbnail_src": "https://scontent-lga3-1.cdninstagram.com/t51.2885-15/s640x640/sh0.08/e35/c125.0.830.830/23348154_1057135264423228_8847456445906550784_n.jpg",
"thumbnail_resources": [],
"is_video": false,
"code": "BbPwpRuFCkP",
"date": 1510169854,
"display_src": "https://scontent-lga3-1.cdninstagram.com/t51.2885-15/e35/23348154_1057135264423228_8847456445906550784_n.jpg",
"caption": "It's #nationalcappuccinoday and there is nothing better to enjoy one with a classic #aquagrill #pumpkinpie. \n#yum #startwithdessert #afternoonsnack #pie #yum #foodart",
"comments":
{
"count": 0
},
"likes":
{
"count": 10
}
}],
"count": 2,
"page_info":
{
"has_next_page": false,
"end_cursor": "1624363260278257469"
}
},
"top_posts": {
"nodes": [
{
"id": "1622809816081533149",
"dimensions": {},
"owner": {},
"thumbnail_src": "https://scontent-lga3-1.cdninstagram.com/t51.2885-15/s640x640/sh0.08/e35/22344919_157157591547812_9215048325810618368_n.jpg",
"thumbnail_resources": [],
"is_video": false,
"code": "BaFYO4Bjojd",
"date": 1507674026,
"display_src": "https://scontent-lga3-1.cdninstagram.com/t51.2885-15/e35/22344919_157157591547812_9215048325810618368_n.jpg",
"caption": "MARSHALL... behind the scenes. It was a pleasure and honor to work with such TALENTED and INCREDIBLE PEOPLE! #bestinthebiz Living my dream! 🙊 #blessed #marshall #thurgoodmarshall #movie @marshallmovie in theaters OCTOBER 13th. A MUST SEE!! 🎭🎭🎭🎭#naacpsecretary #actorlife #livingmydream #waitonit #godsplan #blessings #smooches💋💋💋 @chadwickboseman @reggiehudlin @joshgad @sterlingkbrown @katehudson @jussiesmollet @sophiabush @frequency11 #rogerguenveursmith",
"comments": {
"count": 39
},
"likes": {
"count": 189
}
}
]
}
}
3. Routing, Mapbox Directions and Display
The routes between original waypoints and additional waypoints are created with the Mapbox API as it returns geometry in a GeoJSON format ready to feed into their GL API on the client-side. An aspect I’ve only started experimenting with is which of these places I choose to display and use as the waypoints. As a first test, out of each “nearby” collection, I selected the place with the most photos as well as the place with the most likes. I also included the place with the least photos, to provide an “undiscovered” (or maybe just bad) destination. Often the place with the most number of photos is the same place as the photo with the most likes. If this was the case, I selected the place with the place with the second-most likes.
For further exploration of what places to select as waypoints, I’d like to dig into the captions as well as finding similarities across nearby places. One thing the Facebook API provides is categories associated with each place. These could all be calibrated on the client end. Potential modes could include:
- FOMO: shows all the most popular, current places regardless of distance
- Before-It’s-Cool: the places that have had the most rise in activity lately but aren’t the top destination yet
- Dog-walk: the places with the most number of dog photos
- Hangry: food, and only food
I’d like use additional points along the original route to find other destinations. Rather than source places based on their proximity to the start and end, if an originating route is longer than a certain distance intermediate points could be used to find other locations. Or, it could be constructed as a chain reaction: from start point, find 1 nearby place and then use that as the new input for the next nearby place, and so on and so on, presumably in the direction of intended travel. These are all iterations to further pursue now that I’ve passed the first hurddle of information showing up on a map.
Sidenote: this is the first project I used javascript Promises with and what a world changer. I’m making a number of HTTP requests within for loops and promises simplified handling the asyncronicity. It’s still not the greatest code as I’m passing the response between a few functions between sending it — but it’s functional!
I used Mapbox GL to display the map and its associated data points. The presentation of information leaves a lot to be desired — and more work to make it functional as a directions-provider. For now, the original route, shown in blue, is contrasted with the new route, shown in red. The circle size is based on the number of photos associated with each location. As mentioned earlier, this could be associated with other aspects of the data — baby steps! The non-selected places, but still considered as the top-25 nearby locations, are shown as outlined dots.