‘How Thrilling’ uses the familiar song and dance of Michael Jackson’s “Thriller” to explore how technology can extend the body into many disparate spaces, through many representations, and for many audiences. Through this lens, the project examines how technology standardizes the body.
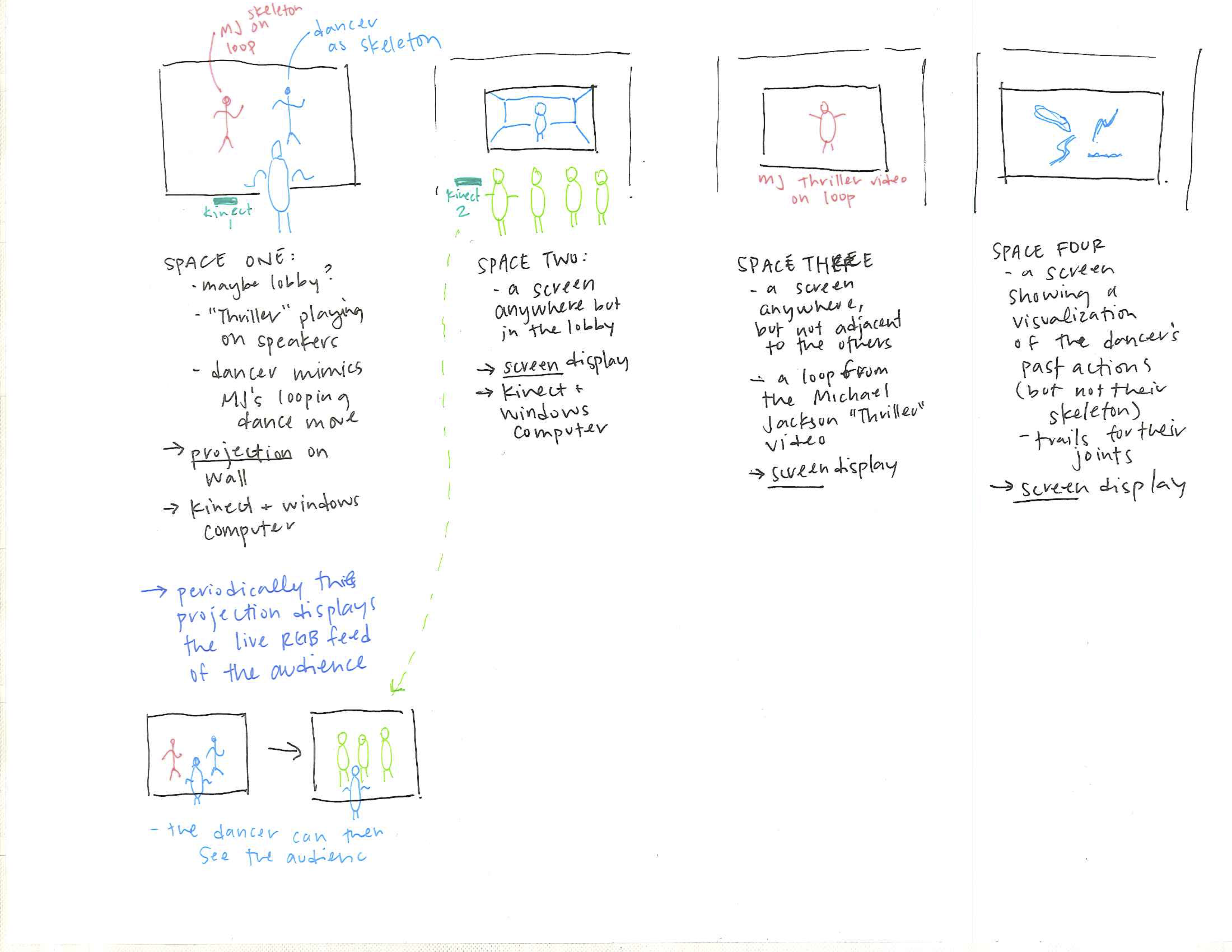
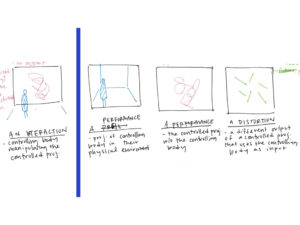
The project is composed of four feeds illustrated in the image above.
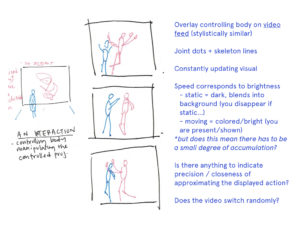
The performing body is presented through two primary representations in feed 1 and 2 respectively: an abstracted stick-figure-like skeleton that is normalized to a single set of proportions and an unmodified in-situ RGB image feed. The abstraction encourages an unselfconciousness of the performer while also highlighting its irregularity of motion in contrast to the precise repetition of Michael Jackson’s looping skeleton. In juxtaposition, the RGB feed–seen only by an audience in an entirely separate space without the accompanying music–highlights the nonconformity of bodies to any form of standardization.
If the performing body closely matches Michael Jackson’s moves or a set time period expires (whichever happens first), the front projection for the performer switches to reveal a live RGB image feed of the audience watching their RGB image feed. For a brief moment, they can communicate across these displays (basically just like Skype, Facetime, etc.) and the audience realizes they are not watching a recording by a live performance. Then, without warning, the projection for the performer reverts back to the abstracted skeletons.
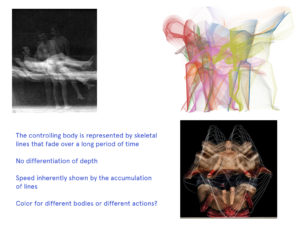
Two additional feeds provide context within the project. Firstly, a constant silent loop of the original Thriller video excerpt gives visual context to the audience watching the RGB image of the performer. They might recognize the actions of the performer in the Michael Jackson video and vice versa. The last feed visualizes the motion trails of the performing body. Without the skeleton, it draws attention to the impercision of our actions despite attempting repetation.
Desired locations:
- Feed 1 (Performer + skeleton projection + audio of Thriller song): first floor lobby
- Feed 2 (RGB image of performer): somewhere on the fourth floor, not too close to the elevators
- Feed 3 (Original Thriller video loop): somewhere closer to the elevators
- Feed 4 (Action trails of performer): somewhere on the fourth floor, proximate but not adjacent to the other screens