Building on my previous work analyzing a large corpus of text, I continued to explore how the connections across various documents could be presented. My prior work on the project focused on constructing the database to allow for as much cross-analysis as I could (at that time) imagine and building out route in express.js and node for accessing the data. With the eventual goal of uncovering a geneaology across the texts, I’ve been looking at both document-level comparisons and sentence-level comparisons.
The focus of this iteration centered on how does the user move across these scales and what information is relevant at these scales?
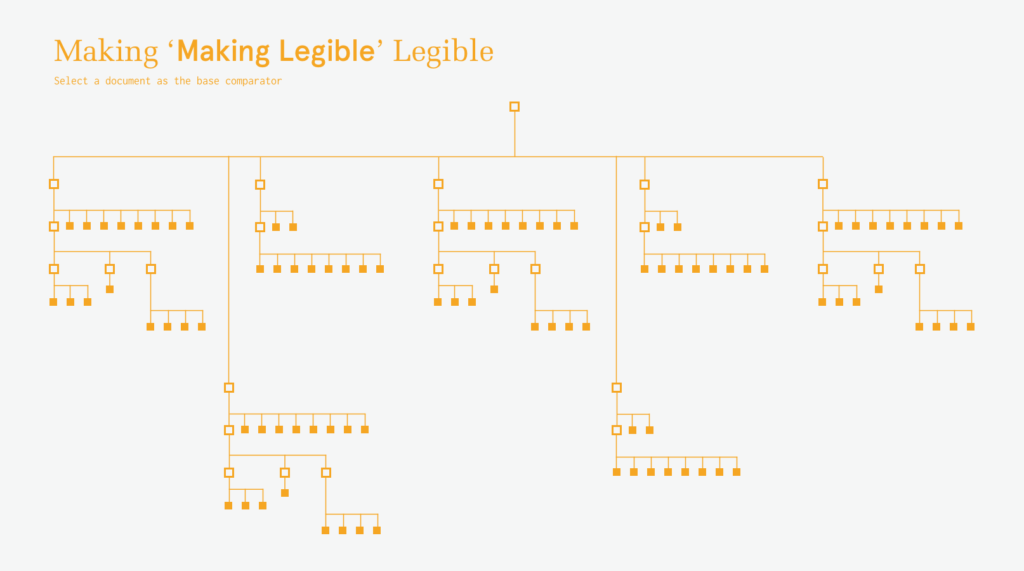
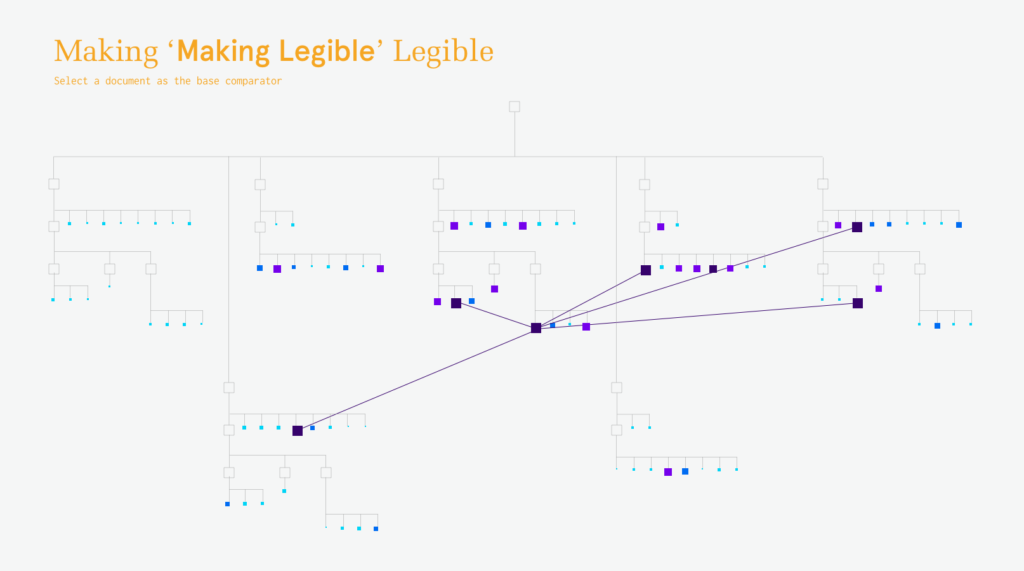
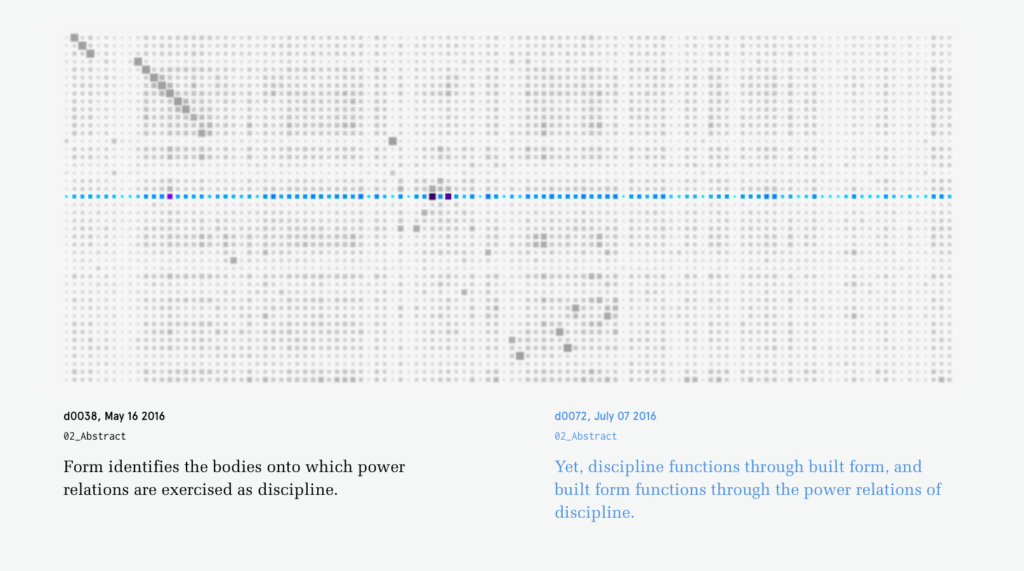
The initial landing page is imagined to be a geneology of documents. Currently, this is shown with simply the established folder-document hierarchies, but I intend to evolve this into a content-based “family tree”. This would also incorporate the aspect of time on the Y axis. (The author often brought in material between documents rather than working out of a single document chain.)When hovering on a document, the similarity to other documents would be shown by size and color. This offers additional information for identifying which document(s) to further investigate.Clicking on a document from the geneaology then compares that document to all other documents at the sentence level. Each compared document is represented by a pixel-array in which each sentence in the document-pair is compared using the dice co-efficient method. This similarity value is again mapped via size and color. When dominant diagonals are evident, it indicates a high level of similarity within a portion of two documents. The jump between the geneaological view to the comparison view seems very disconnected and something that still needs a lot of work.
From the array of arrays, a document-pair comparison can be isolated and the user can now finally read the constituent sentences when hovering. This raises the question of what use is the investigation if the readable sentences are buried so deep in the interaction/piece? On one hand, with 680 documents, it’s imposible to get a sense of the ‘whole picture’ without some form of abstraction. But how can the abstraction still be relevant? For me, within this project, the abstraction is about constructing and revealing relationships across the corpus — in a (not-yet-realized) attempt to get beyond the established document and sentence boundaries.
The above visuals are my ambition for the project while the video below shows its current (rudimentary) coded form.