The structure of data has profound consequences for the design of algorithms.
– “Beyond the Mirror World: Privacy and the Representational Practices of Computing”, Philip E. Agre
To atomize the entire corpus of text, the server processes each document upload to create derivative objects: an upload object, a document object, sentence objects, and word objects. By disassociating the constituent parts of the document, they can then be analyzed and form relationships outside that original container. I’ll discuss those methods of analysis in a later blog post. The focus of this post is how the text is atomized and stored because as Agre pointed out, the organization of data fundamentally underpins the possibility of subsequent analysis.
The individual objects are constructed through a series of callback functions which assign properties. These functions alternate between creating an object with its individual or inherited properties (i.e. initializing a document object with a unique ID, shared timestamp, and content string) and updating said object with the relational properties (i.e. an array of the IDs of all words contained within a document). By necessity, some of these properties can only be added once other objects are processed. The spreadsheet below shows the list of properties and how they are derived.
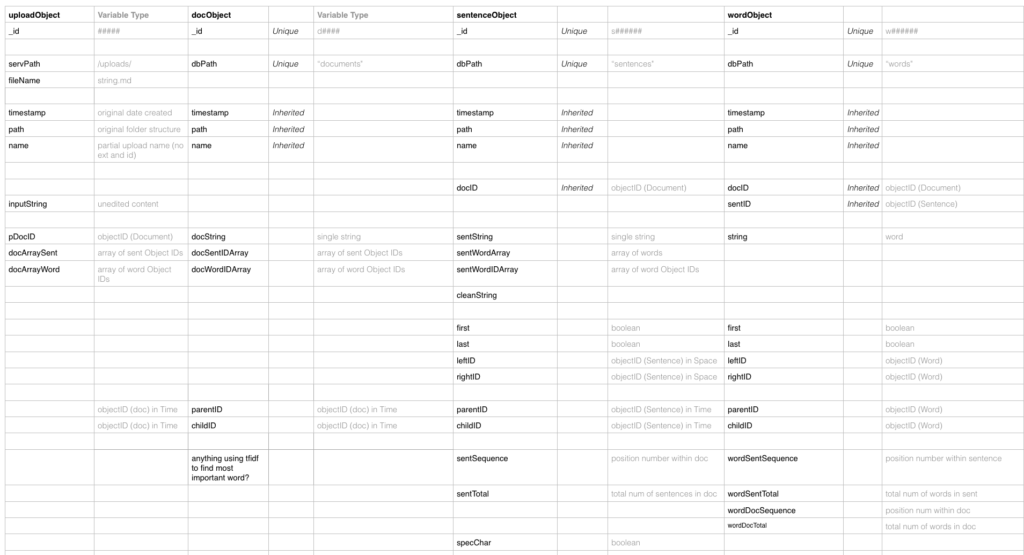
Additionally, as discussed in the previous post, the question of adjacency (or context) is a significant relationship. After the words or sentences are initialized with their unique IDs, the callback function then reiterates over them to add a property for the ID of the adjacent object.
At the sentence level, because the original documents were written in markdown, special characters had to be identified, stored as properties and then stripped from the string. While the “meaning” and usage of these characters is not consistent over time or across documents, they can later be used to identify and extract chunks from document.
Below is an example excerpt of a processed output, from which the individual objects are added to the database. The full code for processing the document upload can be found here.