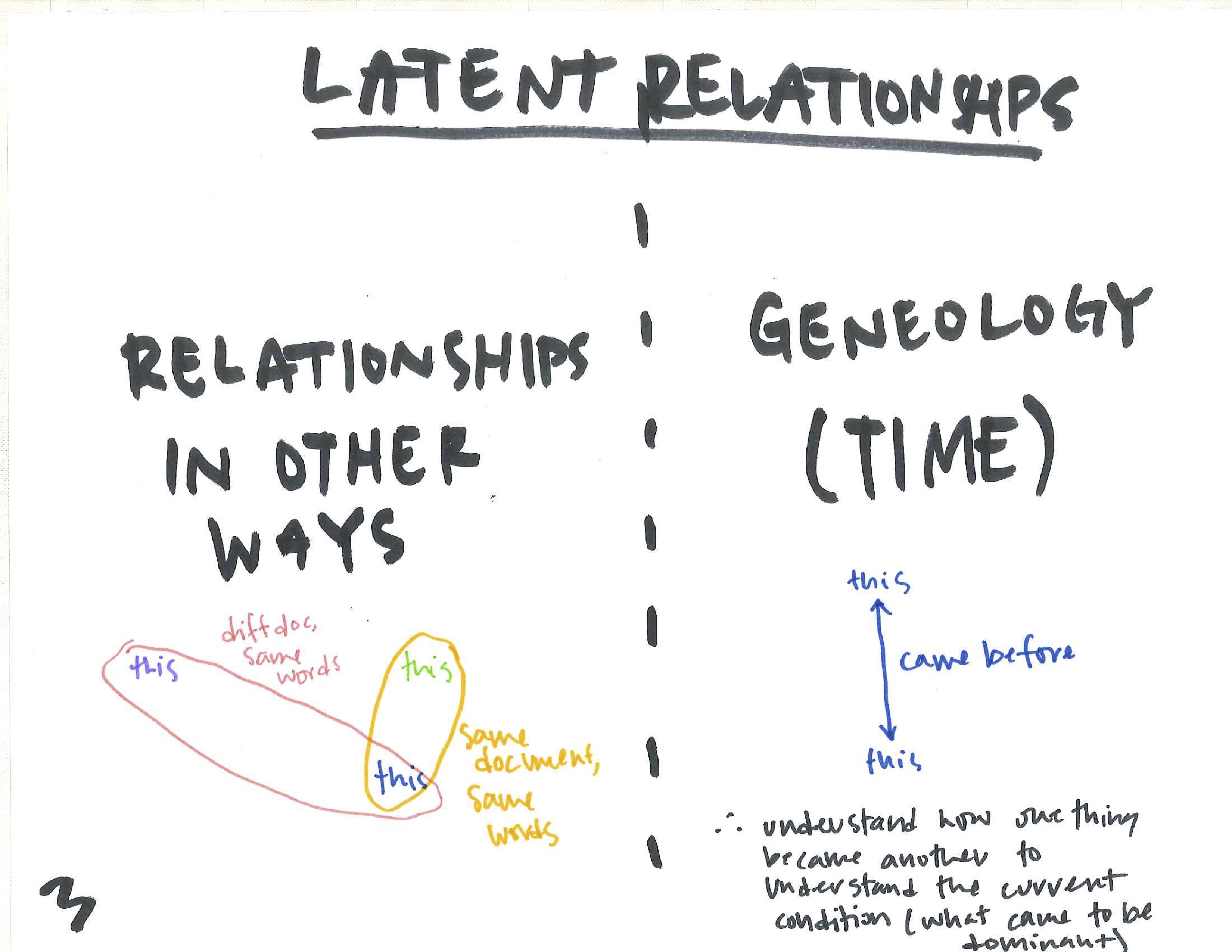
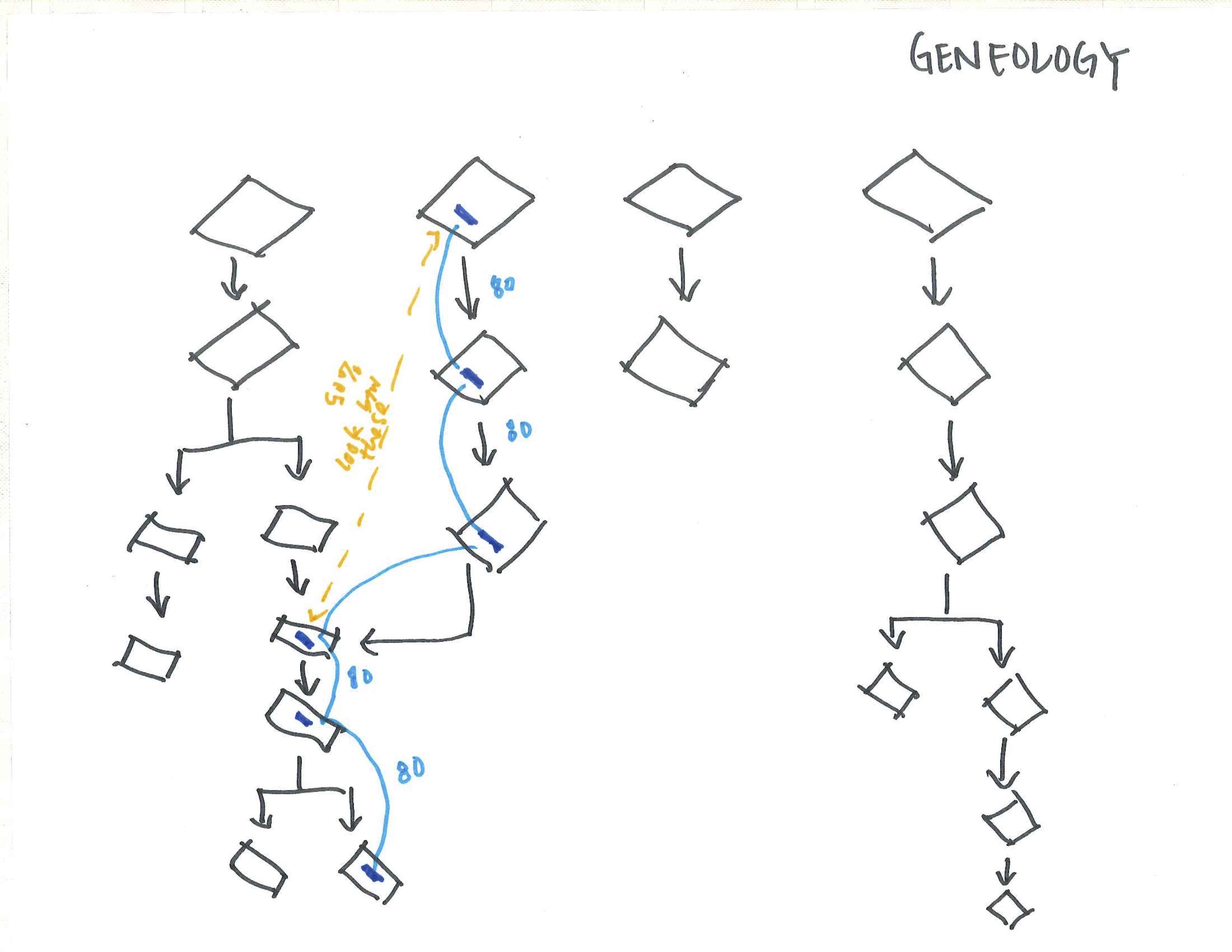
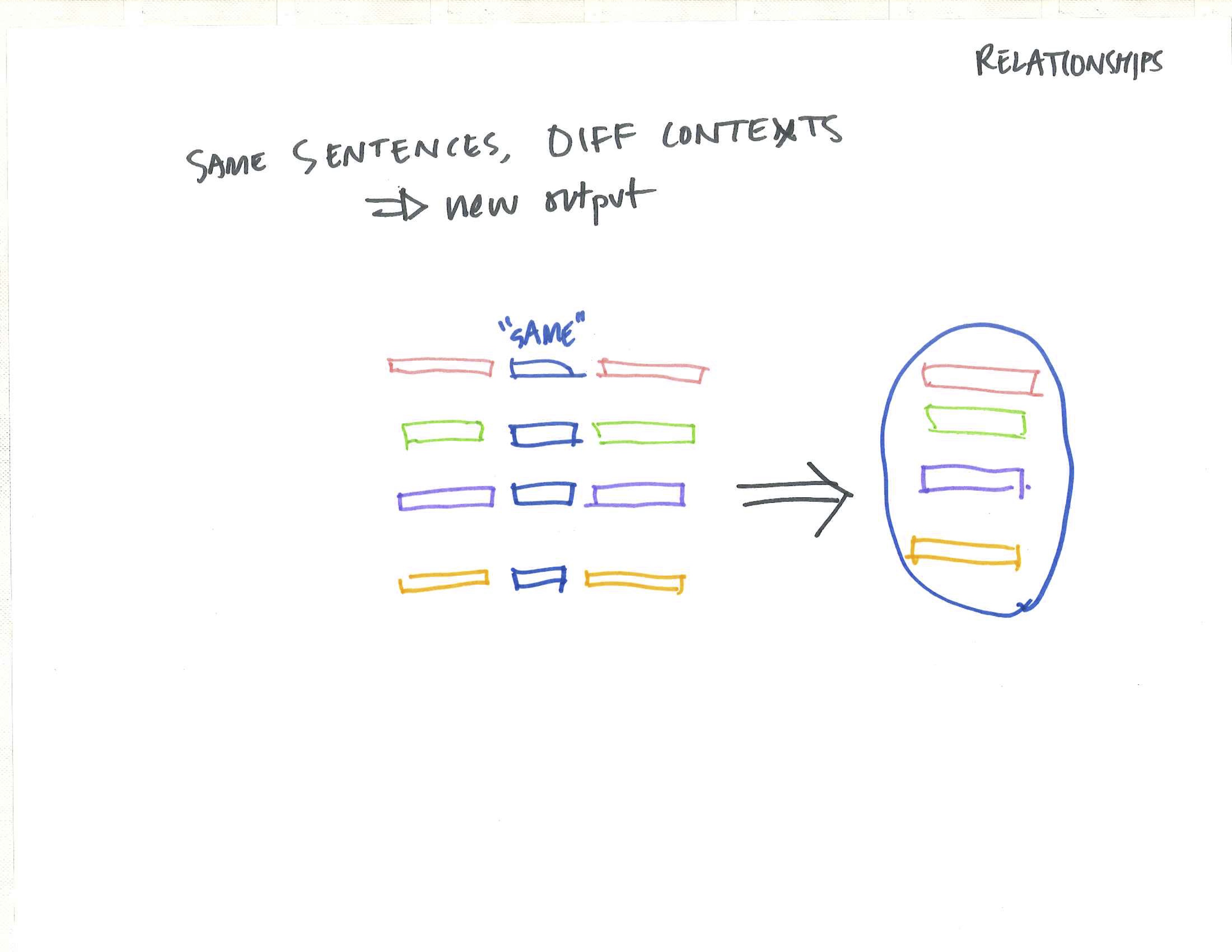
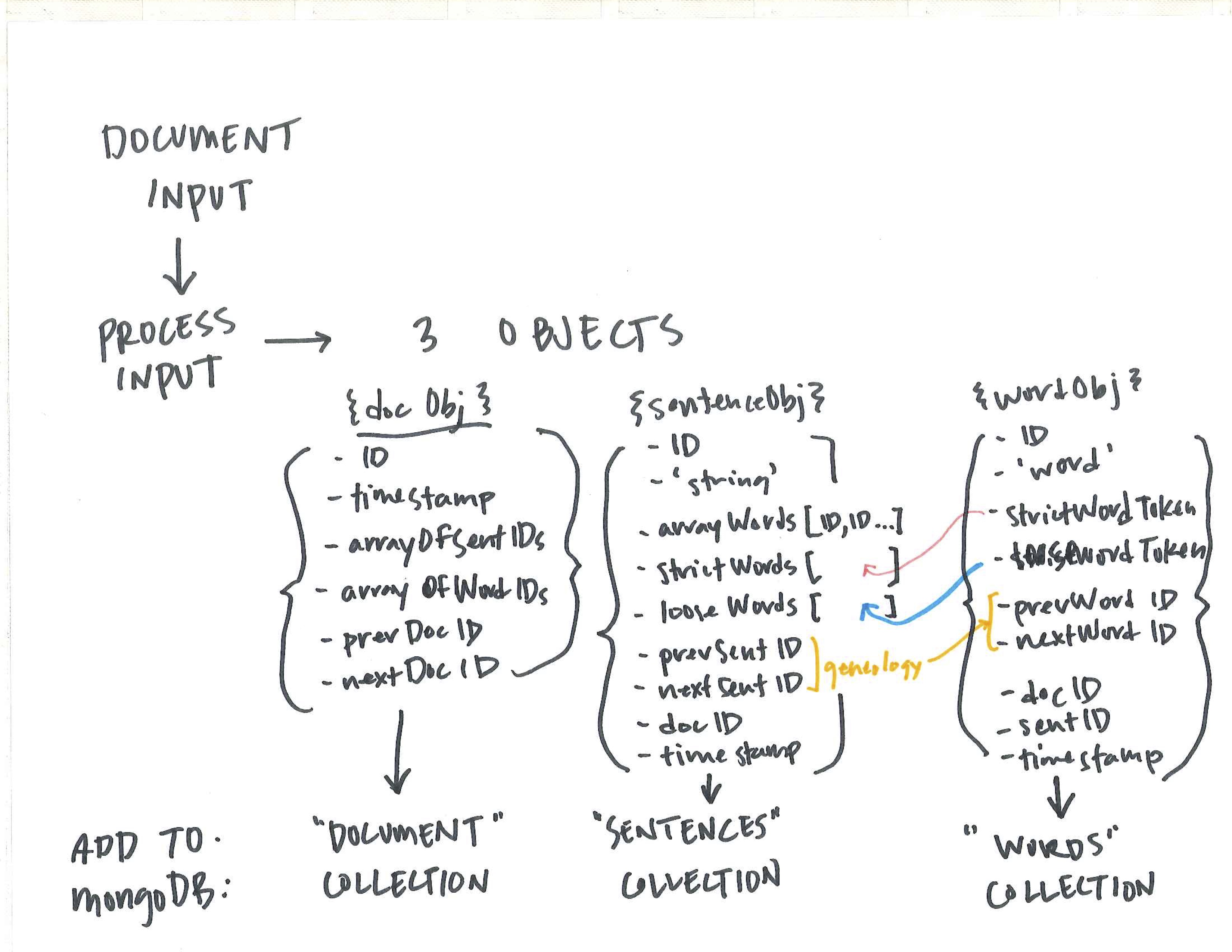
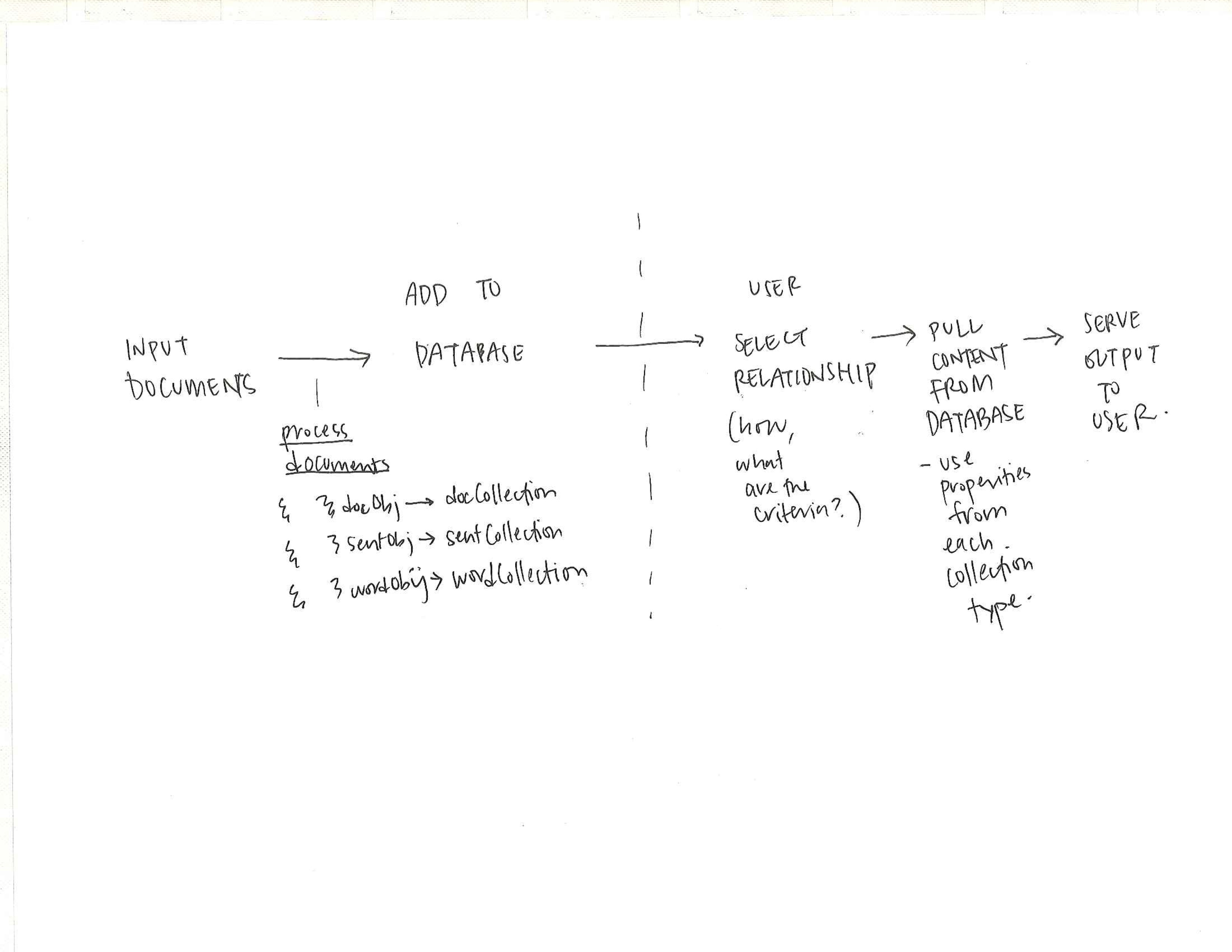
When looking at a large corpus of text, containing documents that were merged, split, duplicated and edited, how can dominate tendancies and thematic pre-occupations be extracted and identified? This project asserts that these latent relationships can only be unearthed by removing the constraining ‘document boundary’ but rather looks at the text though atomizing the content into sentences.
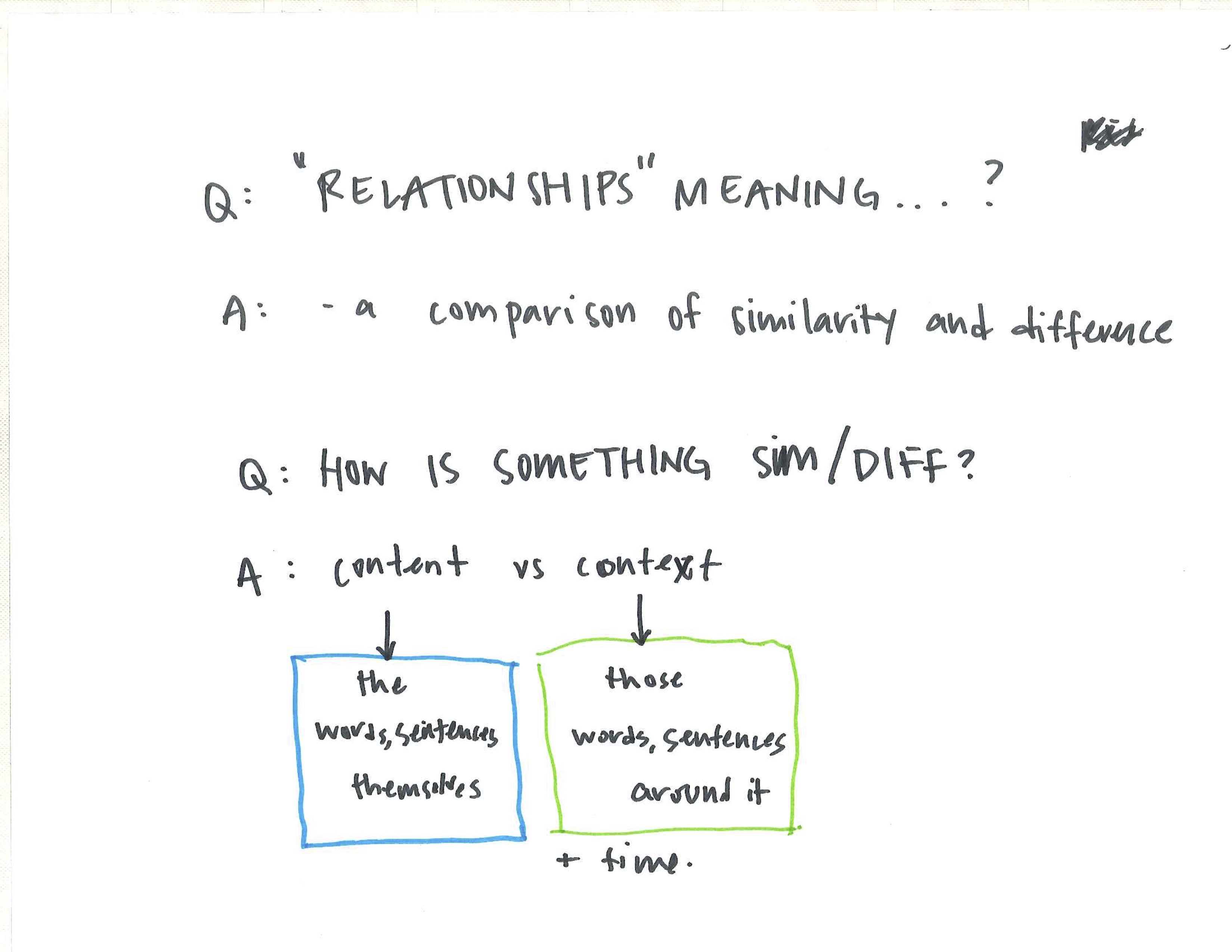
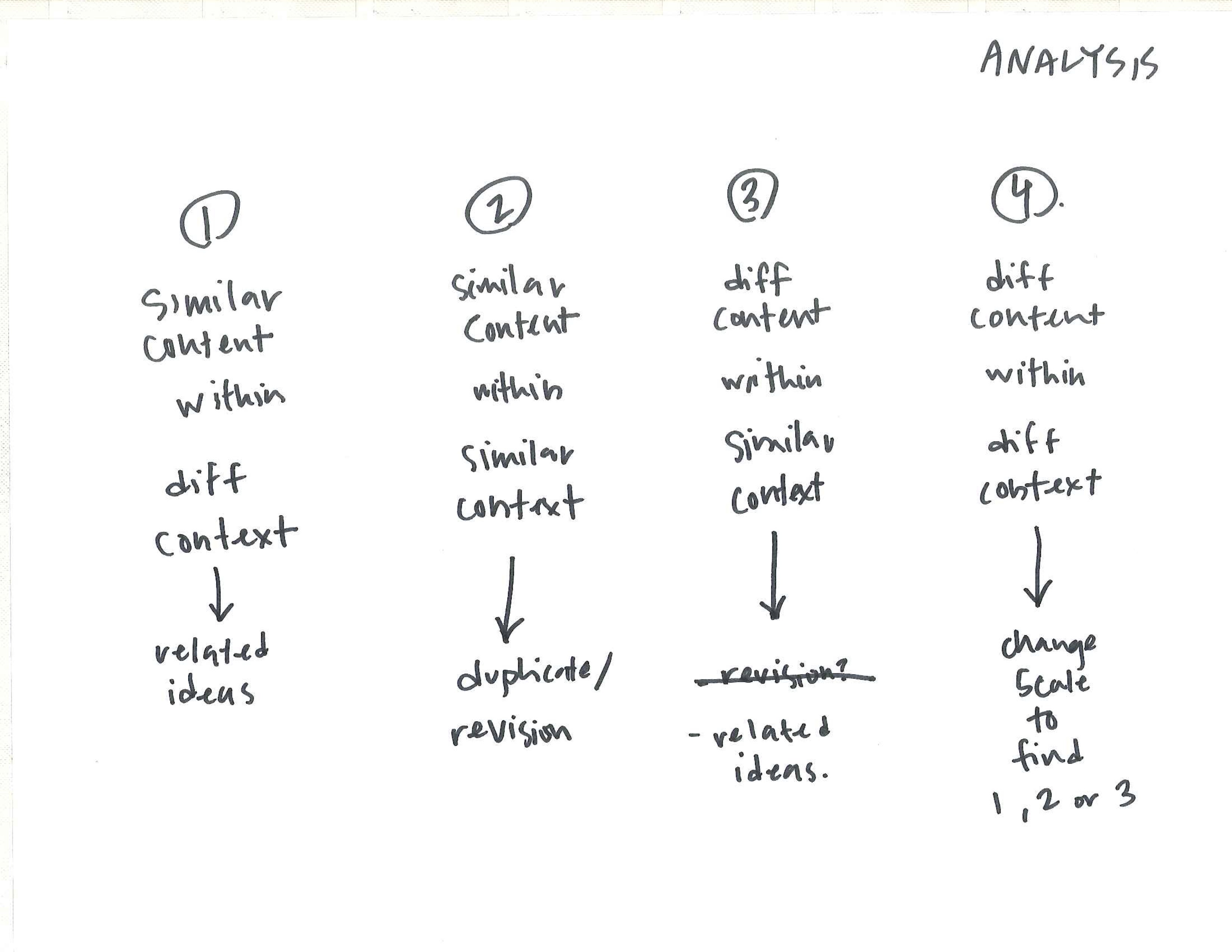
The new relationships across the corpus are found either through the lens of ‘content’ (the words and sentences themselves and their similar counterparts), or through the lens of ‘context’ (the words and sentences around other entities).
The shape of the project is still a bit nebulous, but the images and video recording below explain the conceptual underpins of where the project is headed.




One thought on “Making ‘Making Legible’ Legible: Part 1”
Comments are closed.