What if when clicking links didn’t take you away from a page but layered on new information, creating a sense of trails or context?
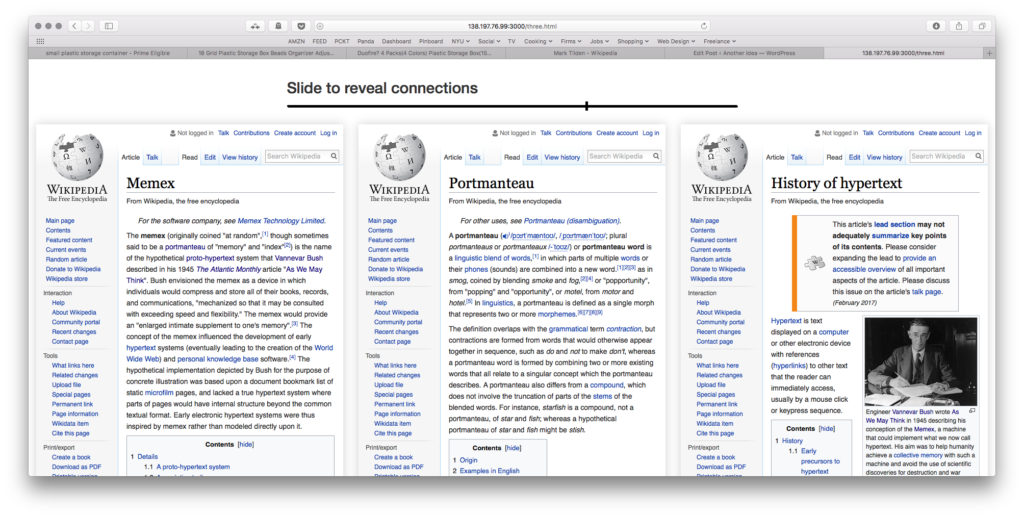
Although a very rudimentary version of this idea, a slider is used to toggle between a single article and a number of linked articles from the first post. A series of iframes load content from Wikipedia.
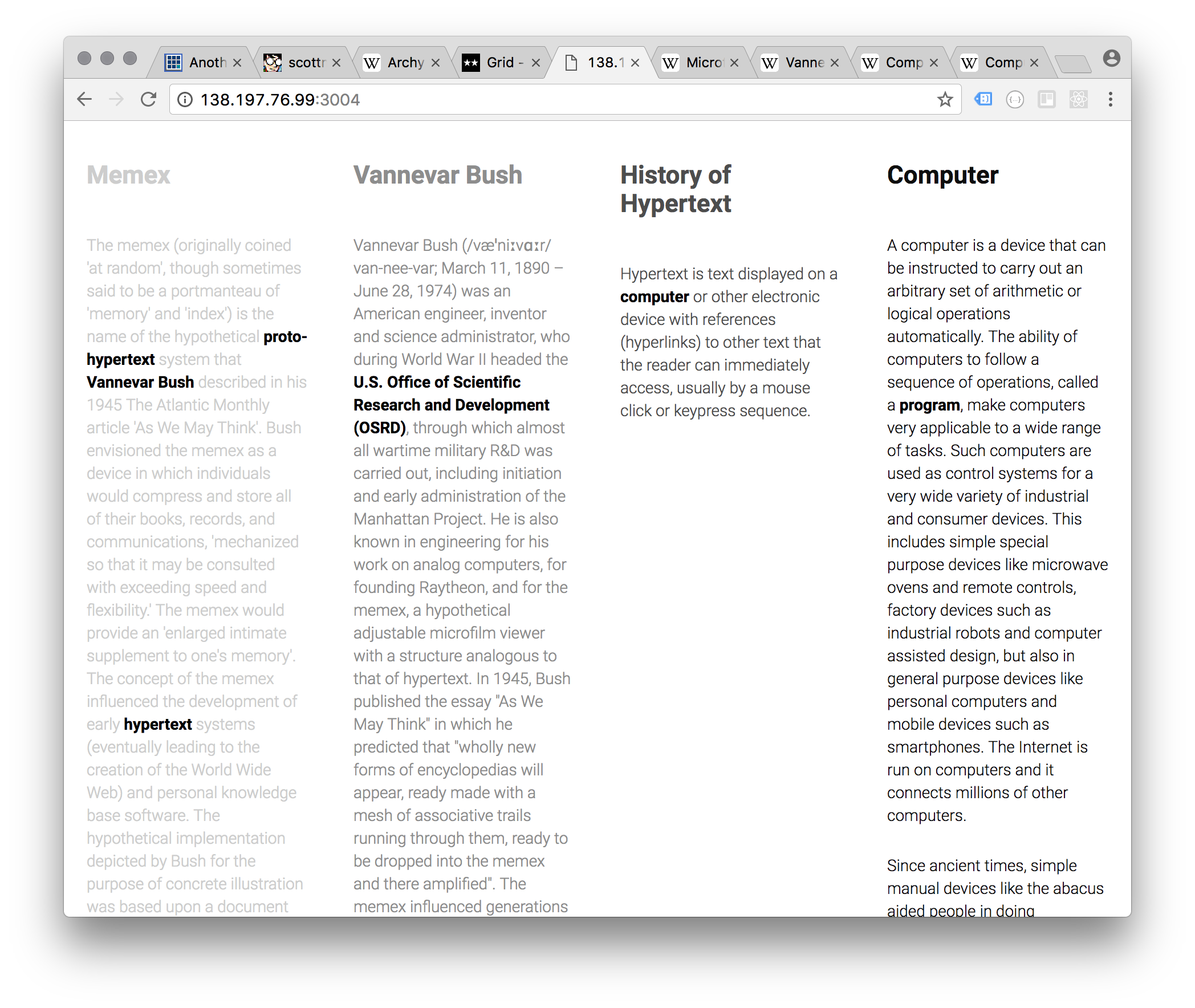
In another iteration, static data is used to test the concept. Two arrays maintain the content: one for ‘viewed content’ (the links clicked) and one for ‘potential content’ (the links that can be clicked). Ideally, this is content is pulled dynamically (i.e. a database of blog posts, etc) but for now Wikipedia is sufficient. When a user clicks a link within an article, the corresponding content from the Potential Data array is added to the Viewed Data array, which populates the HTML page seen by the user. Rather than navigating away from the current block of content, the additional content is added horizontally in a set of increasingly-narrow columns.
(code)
Further Questions:
- Is there a hierarchy of related content? Are certain links of a primary relation, secondary relation, and so on.
- How extensive could the related content be before it becomes illegible? At what point are related links or content entire articles vs excerpts vs images and media?
- How can a website network be zoomable and spatialized to show the connections. See Joni Korpi’s Zoomable UI)